|
Es ist schon wieder soweit. Neben der Breaking-News Mitte der Woche hat sich schon wieder so viel Neues in der KI-Welt getan, dass ich mich kurzerhand dazu entschlossen habe, einen regulären Newsletter zu verfassen.
Den Anfang machen die neuen KI-Kurznachrichten, also Dinge, die spannend genug sind, um sie zu berichten, aber nicht genug Stoff für einen eigenen Beitrag wären. |
| |
OpenAI präsentiert SearchGPT: Hoppla, schon wieder daneben!
Hi hi hi, da hat sich wieder jemand mit falschen Fakten in einer KI-Präsentation blamiert!
OpenAI wollte mit ihrem neuen SearchGPT protzen und - ups - prompt lieferte die KI falsche Festivaldaten. Statt der tatsächlichen Termine des „Appalachian Summer Festivals“ gab SearchGPT die Zeiten an, in denen die Tickethotline Pause macht.
Na, das nenne ich mal eine echte Sommerpause! 🏖️😅
Tja, liebe OpenAI, vielleicht solltet ihr eure KI erstmal zum Ferienjob an eine Festivalhotline schicken, bevor sie die nächste Präsentation versemmelt.
Aber keine Sorge, ihr seid in guter Gesellschaft, Google hat sich hier auch nicht gerade mit Ruhm bekleckert...
Offensichtlich ist es leichter, eine KI zu entwickeln, als ihre Fehler zu beheben. Wer hätte gedacht, dass Faktencheck so 2010 ist? 🕵️♀️🤖
Die gescheiterte SearchGPT-Demo von OpenAI zeigt, wie schwer es ist, KI-Bullshit zu erkennen |
| |
AlphaProof: Ein formaler Ansatz für mathematische Beweise per KI
Dieses neue System kombiniert formale Sprachen mit Reinforcement Learning, um mathematische Beweise zu generieren und zu verifizieren.
Bei der Internationalen Mathematik-Olympiade konnte AlphaProof bereits Aufgaben lösen, die nur wenige menschliche Teilnehmer:innen bewältigten.
Extrem spannend zu lesen, wie dieses System konstruiert ist! |
| |
Metas Llama 3.1 ist da
Meta hat eine neue Reihe von Grundlagenmodellen veröffentlicht, darunter eine beeindruckende Version mit 405 Milliarden Parametern.
Die Modelle zeichnen sich durch Vielseitigkeit in Bereichen wie Mehrsprachigkeit, Programmieren und logisches Denken aus.
Besonders interessant: Meta gibt Einblicke in die Zusammensetzung ihrer Trainingsdaten!

|
| |
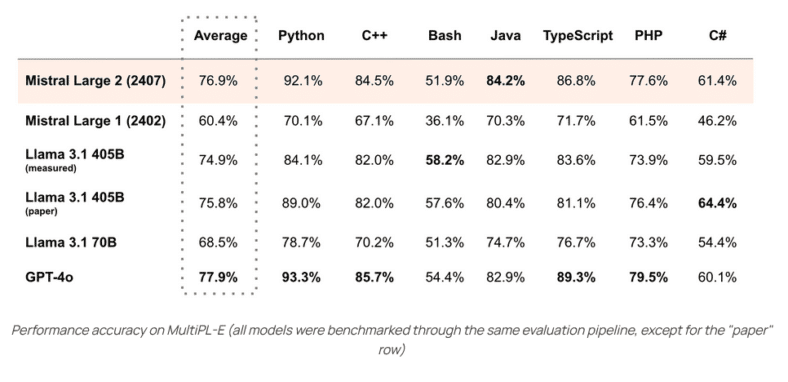
Mistral Large 2
Nur einen Tag nach Llama 3.1 präsentierte Mistral ihr neuestes Modell. Es überzeugt durch ein hervorragendes Verhältnis von Leistung zu Kosten und ist dabei mehr als dreimal kleiner als Llama 3.1. Ein Schwerpunkt lag auf der Verbesserung der Denkfähigkeiten und der Reduzierung von „Halluzinationen“.
|
| |
🚨 Achtung Unternehmen: Der EU AI Act kommt - sind Sie vorbereitet? 🤖📊
In nur 6 Monaten tritt der EU AI Act in Kraft, und er bringt eine oft übersehene Pflicht mit sich: KI-Kompetenz für Mitarbeiter!
👉 Ab Januar 2025 müssen ALLE Unternehmen, die KI nutzen (ja, auch ChatGPT zählt!), sicherstellen, dass ihr Personal über "ausreichende KI-Kompetenz" verfügt.
Was bedeutet das für Sie?
✅ Schulungsbedarf ermitteln
✅ Maßgeschneiderte KI-Trainingsprogramme entwickeln
✅ Kontinuierliche Weiterbildung sicherstellen
Die gute Nachricht: KI-Kompetenz ist nicht nur eine Pflicht, sondern eine Chance!
🚀 Gut geschulte Mitarbeiter können das volle Potenzial von KI ausschöpfen und Ihr Unternehmen an die Spitze der digitalen Transformation führen.
Lassen Sie uns gemeinsam die Zukunft gestalten!
Kontaktieren Sie mich für maßgeschneiderte KI-Kompetenz-Schulungen. |
| |
Fast alle Entwickler:innen nutzen KI-Tools zur Codegenerierung trotz Verboten
Eine aktuelle Studie des Cloud-Security-Unternehmens Checkmarx zeigt, dass 99 Prozent der Entwicklungsteams KI-Tools zur Codegenerierung einsetzen, obwohl 15 Prozent der Unternehmen deren Einsatz explizit untersagen. Diese Ergebnisse verdeutlichen die Diskrepanz zwischen offiziellen Richtlinien und der tatsächlichen Praxis in den Entwicklungsabteilungen.

Die Studie zeigt, dass Unternehmen Schwierigkeiten haben, den Einsatz von generativer KI zu steuern und zu regulieren. Nur 29 Prozent der Unternehmen haben bisher eine Form von Governance für den Einsatz generativer KI-Tools etabliert. In 70 Prozent der Fälle fehlt eine zentrale Strategie, wodurch Kaufentscheidungen oft ad hoc von einzelnen Abteilungen getroffen werden.
Gleichzeitig wächst die Besorgnis über mögliche Sicherheitsrisiken: 80 Prozent der Befragten äußern sich besorgt über Sicherheitsbedrohungen durch die Nutzung von KI durch Entwickler:innen. Besonders beunruhigend sind für 60 Prozent der Befragten potenzielle KI-Probleme wie Halluzinationen.
Trotz der Bedenken besteht Interesse an den Potenzialen generativer KI. 47 Prozent der Befragten sind offen dafür, KI unbeaufsichtigte Änderungen am Code vornehmen zu lassen. Nur 6 Prozent vertrauen KI jedoch nicht bei Sicherheitsmaßnahmen in der eigenen Softwareumgebung.
Ähnliche Ergebnisse lieferte kürzlich der Work Trend Index von Microsoft, den wir hier auch schon besprochen haben. Auch hier zeigte sich, dass viele Mitarbeitende ihre eigenen KI-Tools verwenden, wenn ihnen keine zur Verfügung gestellt werden, und häufig nicht darüber sprechen. Dies blockiert eine systematische Implementierung von generativer KI in Unternehmensprozesse. |
| |
OpenAI plant Entwicklung eines eigenen KI-Chips
Nicht besonders überraschend, um ehrlich zu sein. Google hat schon länger seine TPUs, Apple steigt gerade groß in die Entwicklung von KI-Chips für seine Datencenter ein und Elons KI-Chips von Tesla kommen nun auch X.ai zu Gute.
Doch nun ist es offiziell, dass eben auch OpenAI eigene KI-Chips entwickeln will und dafür Partner sucht. Das wird seinem größten Lieferanten, Nvidia, wahrscheinlich nicht gefallen. |
| |
Sprachmodelle stoßen bei großen Dokumenten an ihre Grenzen
Große Sprachmodelle (LLMs) wie GPT-4 oder Claude 3 werben mit der Fähigkeit, riesige Textmengen zu verarbeiten. Doch wie gut verstehen und nutzen sie diese Inhalte wirklich? Ein neuer Benchmark namens NeedleBench liefert ernüchternde Erkenntnisse.
|
| |
Das Rennen um kleine, effiziente Modelle läuft bereits
Andrej Karpathy, ehemaliger KI-Forscher bei OpenAI und Tesla, erwartet, dass KI-Sprachmodelle in Zukunft kleiner und effizienter statt immer größer werden. Dazu müssen die Trainingsdaten so optimiert werden, dass auch kleine Modelle zuverlässig „denken“ können.
Die großen KI-Modelle seien dennoch notwendig: Sie hätten die Fähigkeit, automatisiert zu helfen, Trainingsdaten zu bewerten und in ideale synthetische Formate umzuwandeln. So könne jedes Modell die Daten für das nächste verbessern, bis der „perfekte Trainingsdatensatz“ erreicht sei.
Auch OpenAI-Chef Sam Altman sieht die Datenqualität als entscheidenden Erfolgsfaktor für das weitere KI-Training. Die Kernfrage sei, wie KI-Systeme aus weniger Daten mehr lernen können, so Altman.
Das ist endlich mal eine gute Einschätzung.
Ich glaube auch, dass die großen LLMs nicht mehr spürbar „intelligenter“ werden, es aber noch sehr viel Potential gibt, diese effizienter und robuster gegenüber Halluzinationen zu machen.
Daneben bekommen wir einen ganzen Zoo aus spezialisierteren Modellen, die wiederum Architektonisch für bestimmte Aufgaben besser geeignet sind, als ein reiner Transformer-Autodecoder.
Quelle: the decoder |
| |
OpenAI präsentiert neue Methode zur Reduzierung von KI-Halluzinationen
OpenAI hat eine innovative Methode entwickelt, um die Verständlichkeit und Überprüfbarkeit von KI-generierten Texten zu verbessern. Diese neue Herangehensweise, bekannt als Prover-Verifier-Spiele, könnte das Vertrauen in KI-Systeme stärken und deren Einsatz in kritischen Bereichen erleichtern.
Bei den Prover-Verifier-Spielen treten zwei KI-Modelle gegeneinander an: Ein „beweisendes“ Modell (Prover) generiert Lösungen für ein Problem, während ein „prüfendes“ Modell (Verifier) diese auf ihre Korrektheit überprüft. Ziel ist es, das Beweismodell so zu trainieren, dass es nachvollziehbare und korrekte Lösungen produziert.
In der Studie nutzten die Forscher von OpenAI ein GPT-4-Modell als Beweiser und ein schwächeres GPT-4-Modell als Verifizierer. Der Beweiser wurde abwechselnd in einer „hilfreichen“ und einer „hinterhältigen“ Rolle trainiert. In der hilfreichen Rolle wurde das Modell belohnt, wenn es korrekte Lösungen lieferte, die vom Verifizierer gut bewertet wurden. In der hinterhältigen Rolle wurde es belohnt, wenn es falsche Lösungen erzeugte, die den Verifizierer täuschten.
Das Ergebnis der Studie zeigte, dass der Verifizierer durch das abwechselnde Training lernte, auch subtile Fehler zu erkennen. Dies führte dazu, dass der Beweiser gezwungen war, immer genauere Lösungen zu produzieren. Die Prover-Verifier-Spiele erreichten so einen guten Kompromiss zwischen Leistung und Verständlichkeit.
Ein besonderer Vorteil der Methode ist, dass sie weniger auf menschliche Anleitung angewiesen ist. Dies ist relevant für die Entwicklung superintelligenter KI-Systeme, die sich zuverlässig an menschliche Werte anpassen müssen. |
| |
Hilft oder schadet uns der EU AI Act? Fest steht: Er kommt!
In den sozialen Netzwerken, allen voran auf LinkedIn, entfacht immer stärker eine Diskussion um den EU AI Act, insbesondere die Gegner argumentieren gerade damit, dass diese Überregulierung der EU dazu führe, Innovation zu verhindern, Unternehmen auszubremsen und für Startups eine unüberwindbare Hürde darstellt.
Von den jüngsten Ankündigungen Apples und Metas, seine neuen KI-Modelle nicht nach Europa zu bringen, fühlt sich diese Fraktion in ihrer Meinung bestätigt.
Ich sehe das Ganze etwas differenzierter und würde sogar behaupten, dass es, wenn Apple und Meta sich nicht an die Regeln des AI Acts halten wollen, (die könnten es zweifelsohne!) dann ist das sogar eine gute Nachricht für die Europäischen Unternehmen, die mit konformen Lösungen weniger Konkurrenz aus den Staaten ausgesetzt sind!
Wir brauchen faire Regeln und dazu gehört auch, dass geklärt ist, wann wer und wozu Trainingsdaten erheben und verwenden darf.
Mistral AI zeigt doch, dass man auch aus der EU heraus wettbewerbsfähige Foundation Models trainieren und sowohl in Open Source, als auch kommerziellen Varianten bereitstellen kann.
Auch wenn sich Aleph Alpha so langsam als überbewerteter „Cash Grab“ entpuppt, der nun lieber Dienstleistung a la Accenture verkauft, anstatt in Grundlagenforschung und Foundation Modelle mit dem Fokus auf europäische Sprachen zu investieren.
Auf der anderen Seite: OpenAI und Anthropic verbrennen gerade Milliarden für KI-Entwicklung und -Betrieb. Wer garantiert denn, dass sich diese massiven VC-Gelder jemals auszahlen? |
| |
Inhaber Kai Spriestersbach
Galgenäcker 7, 97903 Collenberg
Impressum: afaik.de/impressum
| |
|
Falls Du Dich fragst, wieso Du diesen Newsletter erhältst:
Aus SEARCH ONE wurde AFAIK.
Du hast Dich in der Vergangenheit für meinem Newsletter angemeldet, damals wahrscheinlich noch unter search-one.de. Mittlerweile heißt mein Blog jedoch AFAIK, weshalb auch der Absender meiner Newsletter nun von [email protected] auf [email protected] umgestellt wurde.
Kai Spriestersbach |
| |
|








