Der Sommer ist mitten im Gange, doch von KI-Sommerloch keine Spur! Es gibt eine Menge spannender News Rund um die Themen ChatGPT, KI und Co.
Für alle Buchkäufer und Newsletter-Abonnenten habe ich am Ende dieses Newsletter wieder die heißesten News und KI-Updates eingefügt, die ihr absofort auch im Login-Bereich auf meiner Webseite finden könnt.
Lese die neuesten Artikel im Magazin
Zu Gast im OMR Education Podcast: Einblick in ChatGPT und wie Marketer davon profitieren können
Es gibt mal wieder ein paar Neuigkeiten für alle Nutzer von ChatGPT: Das Ziel des jünstigen Updates ist es, den Schreibenden die Angst vor dem leeren Chat zu nehmen und den Einstieg in das Modell zu erleichtern. Außerdem möchte OpenAI die Benutzerfreundlichkeit von ChatGPT weiter verbessern.
Wenn man ohne eine spezifische Aufgabe oder Frage in ChatGPT einloggt, kann man nun auf einen zufälligen Vorschlag für einen Prompt von OpenAI klicken:
Allerdings sind diese Vorschläge derzeit noch recht zufällig und möglicherweise nur bedingt hilfreich. Dennoch zeigt dies die Vielfalt von ChatGPT und OpenAI plant in Zukunft personalisierte Prompts basierend auf dem Nutzerverhalten anzubieten, ähnlich der Autovervollständigung bei der Google-Suche.
Eine weitere Verbesserung ist die Integration von Vorschlägen für Nachfragen in laufende Konversationen. ChatGPT bietet nun Antwortvorschläge auf laufende Chats an, um die Interaktion und Vertiefung der Konversationen zu erleichtern. Dies erinnert an eine Funktion, die Google bereits in seiner generativen KI-Suche „SGE“ testet.
Eine besonders bemerkenswerte Neuerung ist die Möglichkeit, mehrere Dateien hochzuladen und diese parallel zu analysieren. Mit dieser aus dem Code-Interpreter bekannten Funktion kann ChatGPT nun Daten aus verschiedenen Quellen verarbeiten und Aufgaben entsprechend bearbeiten.
Ein praktisches Beispiel ist die Generierung einer Zusammenfassung aus zwei hochgeladenen Word-Dokumenten oder den Vergleich von Informationen in beiden Dokumenten.
Ab sofort starten Pro-Benutzer direkt mit GPT-4, anstatt das Modell zuvor auswählen zu müssen. Zudem bleibt der Login jetzt dauerhaft über zwei Wochen hinaus bestehen.
Für eine noch komfortablere Bedienung wurden neue Tastaturkürzel hinzugefügt, wie beispielsweise ⌘ (Strg) + Shift + C zum Kopieren von Codeblöcken. Eine vollständige Liste der Tastaturkürzel kann durch ⌘ (Strg) + / abgerufen werden.
Diese spannenden Neuerungen werden nach und nach weltweit für alle Nutzer von ChatGPT ausgerollt.
Custom instructions für ChatGPT
OpenAI führt benutzerdefinierte Anweisungen ein, um den Nutzern mehr Kontrolle darüber zu geben, wie ChatGPT antwortet. Darüber lassen sich nun Präferenzen festlegen, die ChatGPT bei allen zukünftigen Unterhaltungen berücksichtigen wird. Diese Funktion ist derzeit noch in der Beta-Phase des Plus-Tarifs verfügbar und wird in den kommenden Wochen auf alle Nutzer ausgeweitet. In meinem Account ist die Funktion derzeit leider noch nicht aktiviert.
Über Felder: „Was möchtest du, dass ChatGPT über dich weiß, damit du besser antworten kannst?“ und „Wie möchtest du, dass ChatGPT antwortet?“ lassen sich benutzerdefinierte Anweisungen definieren, die für sämtliche neuen Chatverläufe gelten sollen.
Achtung: Vor allem während der Beta-Phase interpretiert ChatGPT benutzerdefinierte Anweisungen jedoch nicht immer perfekt. Es kann also durchaus vorkommen, dass es Anweisungen ignoriert oder sie anwendet, obwohl sie nicht sinnvoll in einem bestimmten Kontext sind.
Wozu das Ganze?
In den benutzerdefinierten Anweisungen kannst du generelle Vorgaben oder Anforderungen angeben, die ChatGPT bei der Erstellung seiner Antworten berücksichtigen soll. So kannst du beispielsweise dafür sorgen, dass die Antwort immer auf Deutsch erfolgt, oder immer in einer bestimmten Art und Weise formuliert wird.
OpenAI zieht AI Classifier zurück
Als ich Anfang des Jahres mein Buch über ChatGPT & Co. geschrieben habe, habe ich mich auch damit auseinander gesetzt, ob Suchmaschinen wie Google oder Lehrkräfte an Schulen und Hochschulen zuverlässig erkennen können, ob ein Text vollständig oder zumindest teilweise von einer generativen KI wie GPT-4 oder Ähnlichem geschrieben wurde.
GPTZero, eine der ersten Ansätze, die mir in meiner Recherche aufgefallen sind, war zum damaligen Zeitpunkt noch nicht öffentlich verfügbar, also habe ich mich in meinem Buch mit den theoretischen Hintergründen und dem aktuellen Stand der KI-Forschung beschäftigt und mir die Frage gestellt, ob es überhaupt möglich sein kann und ob sich der Aufwand einer KI-Content-Erkennung, beispielsweise für Suchmaschinen überhaupt lohnt.
Seit dem Erscheinen meines Buches hat OpenAI seinen AI Classifier bereits Mangels Treffsicherheit zurück gezogen. Das Programm sollte KI-erzeugte Texte erkennen. Das klappte jedoch nicht zuverlässig genug: „Der AI Classifier ist nicht mehr verfügbar aufgrund seiner geringen Genauigkeit“, gesteht OpenAI ein.
Wenn generative KI-Modelle verwendet werden, um Texte zu generieren, ist es rein mathematisch äußerst schwierig, diese mit Sicherheit zu erkennen. Denn selbst wenn wir die Modelle deterministisch machen würden (indem wir eine Temperatur von 0 verwenden) würden sie immer noch eine sehr lange und einzigartige Kette von Token generieren. Diese Kette würde jeden möglichen Text enthalten, den das Modell jemals generieren könnte, und wäre dementsprechend extrem lang.
Um zu überprüfen, ob ein bestimmter Text von der KI generiert wurde, müssten wir also die gesamte Tokenkette vorhersagen oder alle möglichen Kombinationen von Token speichern und den zu prüfenden Text damit vergleichen. Dies erfordert enorme Speicher- und Rechenkapazitäten, die praktisch nicht umsetzbar sind.
Darüber hinaus verhalten sich KI-Modelle probabilistisch, nicht deterministisch. Das bedeutet, dass sie die nächsten Token nur mit bestimmten Wahrscheinlichkeiten vorhersagen, aus denen das Modell dann zufällig auswählt. Bei einer Auswahl von zehn möglichen Worten ergeben sich mehr Kombinationsmöglichkeiten als die Anzahl der Atome im Universum!
Es ist auch wichtig zu beachten, dass jedes KI-Modell unterschiedliche Parameter und Gewichtungen besitzt, was zu unterschiedlichen Wahrscheinlichkeiten und Ergebnissen führt. Daher wäre eine Methode, die für ein Modell funktioniert, nicht unbedingt auf andere Modelle anwendbar.
Zusammenfassend lässt sich sagen, dass aufgrund der Komplexität der generativen KI-Modelle, ihrer probabilistischen Natur und der enormen Anzahl von möglichen Kombinationen eine sichere Erkennung von KI-generierten Texten äußerst herausfordernd ist.
Detektorsysteme wie diese verdienen unser Vertrauen nicht. Bei fälschlicherweise erkannten KI-Texten kommt die Frage nach der Genauigkeit und Zuverlässigkeit auf.
Kai Spriestersbach
Mein Tipp lautet daher: Probiert es am besten selbst aus und zeigt Euren Kunden und Vorgesetzten, dass diese Tools grundlegende Schwächen haben.
Lost in the Middle: Arbeit mit sehr langen Texten
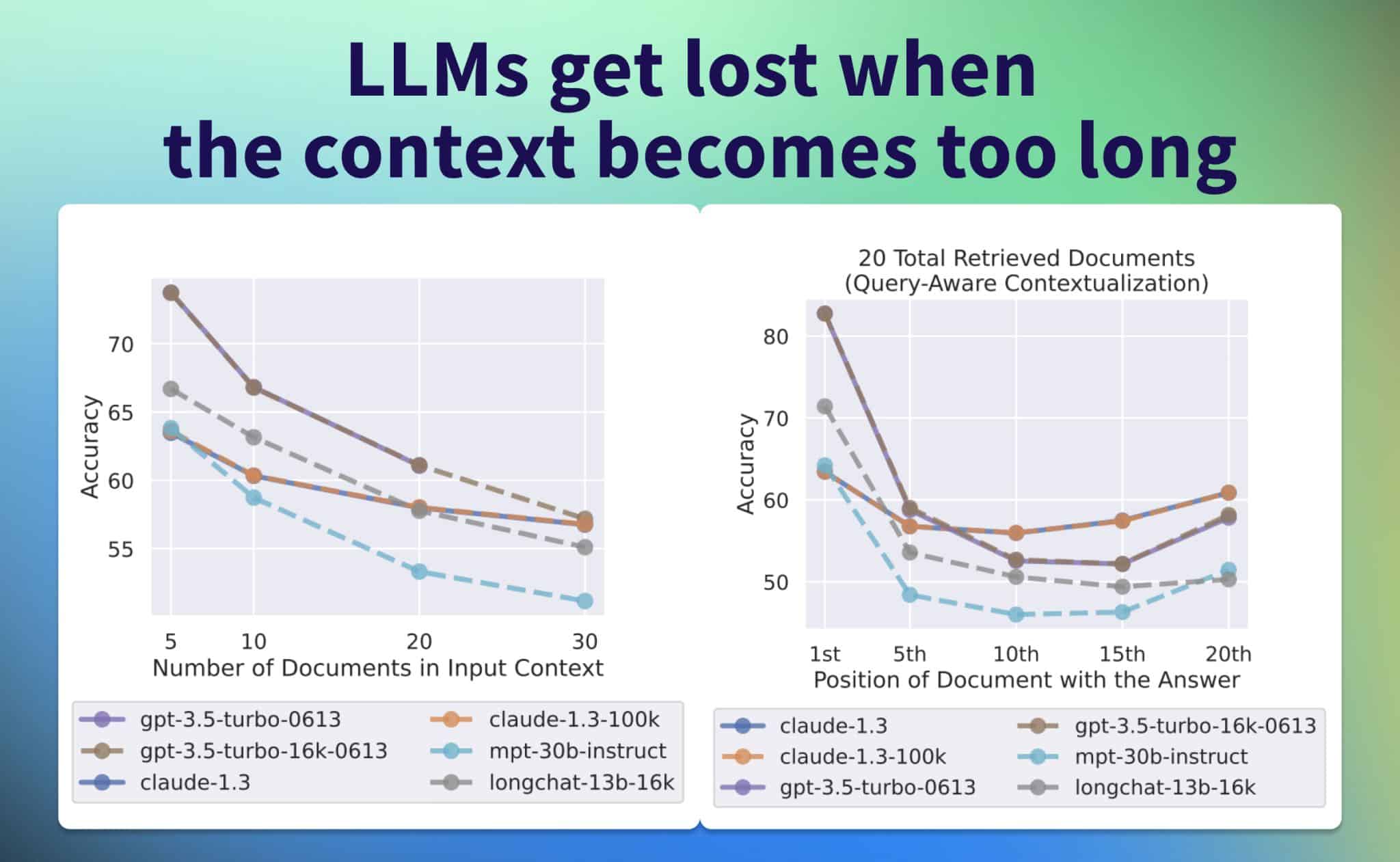
Obwohl neuere Sprachmodelle in der Lage sind, lange Kontexte als Eingabe zu verwenden, ist noch relativ wenig darüber bekannt, wie gut sie diese Kontexte auch tätsächlich nutzen. Ein Forscherteam analysierte nun die Leistung von Sprachmodellen bei Aufgaben, bei denen relevante Informationen im Eingabekontext identifiziert werden müssen. Die Studie mit dem Titel „Lost in the Middle: How Language Models Use Long Contexts“ (Verloren in der Mitte: Wie Sprachmodelle lange Kontexte nutzen) von Forschern der renommierten Stanford-Universität liefert interessante Einblicke in die Nutzung von langen Kontexten durch Language Models (LLMs).
In der Studie wurde analysiert, wie LLMs Informationen innerhalb des langen Kontextes nutzen, um relevante Informationen zu identifizieren und diese dabei bewertet wurden. Dabei wurden sowohl Open-Source- als auch Closed-Source-Modelle getestet, darunter MPT-30B-Instruct, LongChat-13B(16K), GPT-3.5-Turbo von OpenAI und Claude 1.3 von Anthropic.
Die Forscher untersuchten die Leistung der Modelle bei der Beantwortung von Fragen mit mehreren Dokumenten als Kontext und einer richtigen Antwort, deren Position im Input-Prompt variiert wurde. Dabei stellten sie fest, dass die besten Ergebnisse erzielt wurden, wenn die relevanten Informationen am Anfang des Kontexts standen.
Mit zunehmender Länge des Kontexts sank die Leistung der Modelle jedoch. Ebenso wirkte sich eine zu hohe Anzahl abgerufener Dokumente negativ auf die Leistung aus. Interessanterweise brachten Modelle mit erweitertem Kontext (z. B. GPT-3.5-Turbo vs. GPT-3.5-Turbo (16K)) keine signifikante Verbesserung, wenn der die Länge des Inputs das Kontextfenster nicht überstieg.
Ein vielversprechender Ansatz zur Verbesserung der Leistung ist der Einsatz von Cross-Encodern (Ranking) zur Optimierung des Abrufs und der Prompt-Erstellung, was die Leistung um bis zu 20% steigern könnte. Praktisch bedeutet das, dass man zunächst den für die Antwort relevanten Teil des Textes identifiziert und anschließend die Antwort mit diesem Teil als Input generiert. Die Studie verdeutlicht die potenziellen Vorteile der Kombination von Retrieval und Ranking, insbesondere in Bezug auf die RAG (Retrieval-Augmented Generation) für die Beantwortung von Fragen.
Llama 2 ist da! Warum Metas neuer GPT-Konkurrent so wichtig ist
Bisher hatte ChatGPT einen enormen Vorteil gegenüber seinen Konkurrenten, selbst gegenüber großen Unternehmen wie Google, denn kaum ein Konkurrenzmodell lässt sich derzeit kommerziell nutzen. Doch Meta hat kürzlich die neueste Version seines KI-Modells, Llama 2 (Large Language Model Meta), angekündigt und gleichzeitig das Modell für Entwickler kostenlos zugänglich gemacht, und dies sowohl für Forschungszwecke als auch kommerzielle Anwendungen!
In diesem Jahr könnten wir möglicherweise zum ersten Mal die größte Herausforderung für OpenAIs Dominanz in der Welt der generativen KI erleben.
Meta hat soeben LLaMa 2 veröffentlicht, den neuen, hochmodernen offenen LLM. LLaMA 2 ist die nächste Iteration von LLaMA und kommt mit einer kommerziell freundlichen Lizenz. LLaMA 2 gibt es in 3 verschiedenen Größen, 7B, 13B und 70B. Die 7B & 13B nutzen dieselbe Architektur wie LLaMA 1 und sind ein 1:1 Ersatz für die kommerzielle Nutzung!
Meta und Microsoft haben mit Llama 2 ein Open Source KI-Modell geschaffen, das sich tatsächlich mit ChatGPT messen kann und das quasi kostenlos auf eigener Hardware genutzt werden kann.
Eine Einschränkung gibt es jedoch: Obwohl Llama 2 Open Source ist, benötigen Unternehmen mit über 700 Millionen monatlich aktiven Nutzern eine spezielle Erlaubnis von Meta, um es zu verwenden. Hier will man sich offenbar über zu große Konkurrenz absichern.
Außerdem verfügt das KI-Modell nicht über eine benutzerfreundliche Schnittstelle wie ChatGPT, da es auf technischere und geschäftliche Anwendungsfälle abzielt. Mit einem entsprechenden Interface ausgestattet, könnte Llama 2 jedoch tatsächlich ein vielversprechender ChatGPT-Konkurrent werden. Erste Stimmen behaupten, es hätte die gleiche Leistungsfähigkeit wie ChatGPT.
„Es ist ein großer Schritt vorwärts für Open Source und ein harter Schlag für die Anbieter von Closed Source, da die Verwendung dieses Modells den meisten Unternehmen eine deutlich höhere Anpassungsfähigkeit und geringere Kosten bietet“, schrieb Nathan Lambert, Forscher bei der KI-Firma Hugging Face, kürzlich in einem Substack-Beitrag.
Meta und sein Partner Microsoft haben erklärt, dass ihre Zusammenarbeit Entwicklern ermöglicht, Microsoft Azure zu nutzen, um in Llama 2 zu entwickeln. Dadurch erhalten sie nicht nur Zugang zu Cloud-nativen Tools, sondern können das Programm auch optimal lokal unter Windows ausführen. Llama 2 ist jedoch bereits bei verschiedenen Anbietern verfügbar, darunter Amazon Web Services (AWS) und Hugging Face, was seine Glaubwürdigkeit bei Entwicklern unterstreicht.
Bevor wir sicher wissen, wie leistungsfähig Llama 2 im Vergleich zu ChatGPT ist, müssen wir noch etwas abwarten, aber vorerst scheint es zumindest vielversprechend zu sein.
Forscher der Stanford University und der UC Berkeley haben die von GPT-4 generierten Antworten über Monate untersucht und behaupten in ihrem Paper, das LLM lässt nach und wird immer schlechter. Das Ganze ist natürlich Wind in den Segeln der Kritiker und auch OpenAIs Konkurrenz nutzt die Veröffentlichung für eine größere PR-Welle.
Doch schaut man sich das Paper und die darin gestellten Fragen genauer an, kommt man zu einem vollkommen anderem Ergebnis. Daher habe ich hierzu einen eigenen Blogbeiträg verfasst: