Es ist mal wieder Zeit für einen Grundlagenartikel. Heute erkläre ich, wie Textgenerierung mit großen Sprachmodellen wie GPT-3, GPT-4, Gemini, Llama 2 und Co. funktioniert. Übrigens: Alle in meinem Artikel „Die besten Tools für die KI-Text-Generierung“ vorgestellten Tools arbeiten nach den gleichen Prinzip:
Es wird auf Basis des Prompts und des bereits erzeugten Outputs jeweils das nächste Wort vorhergesagt. Der Algorithmus hat durch das Training mit sehr großen Textmengen gelernt, welches Wort mit größter Wahrscheinlichkeit das Nächste.
Dabei beachtet der Algorithmus von LLMs, also den sogenannten großen Sprachmodellen wie GPT-3, GPT-4 und Co. aber einen größeren Kontext, also nicht nur das vorherige Wort, sondern mehrere hundert, ja sogar tausend Wörter davor. Diese Reihe an Wörtern, bezeichnet man im Zusammenhang mit großen Sprachmodellen auch als Kontext-Fenster.
Liefert man als „Hello“ als Input, wird GPT das Wort finden, das in allen Trainingstexten am häufigsten nach dem Wort „Hello“ vorkam und dieses Wort ausgeben. Sagen wir einfach mal das wäre „Bob“. Für das nächste Wort, ist dann „Hello Bob“ der Input und der Algo findet das Wort mit der höchsten Wahrscheinlichkeit, das danach stehen würde, und so weiter.
Genau genommen arbeiten Modelle der GPT-Familie jedoch nicht mit Worten, sondern mit Token. Token sind eine feste Liste von Zeichenfolgen, die besonder häufig im Trainings-Text vorkommen. Die Modelle verstehen die statistischen Beziehungen zwischen diesen Token und generieren Text, in dem sie das nächste Token in einer Folge von Token produzieren.
Mit diesem Tool von OpenAI lässt sich nachvollziehen, wie ein Text in Token umgewandelt wird, und damit die Gesamtzahl der Token in diesem Text ermitteln. Eine Faustregel besagt, dass ein Token im Allgemeinen etwa 4 Zeichen Text für einen gewöhnlichen englischen Text entspricht. Dies entspricht etwa ¾ eines Wortes (also 100 Token ~= 75 Wörter).
Im folgenden Beispiel sieht man sehr schön, dass besonders häufige, kurze Wörter einem Token entsprechen und seltenere Wörter aus mehreren Token zusammengesetzt werden:
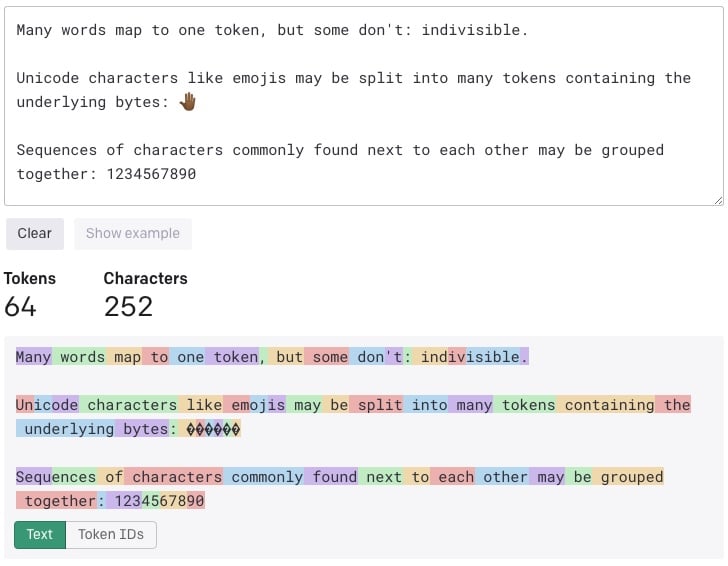
Was sind GPT-3, GPT-4 und Co. eigentlich?
GPT-4 bezeichnet die neueste Generation des Sprachverarbeitungsmodell von OpenAI, eines auf „Natural Language Processing“, kurz NLP spezialisierten Unternehmens. Diese Algorithmen übertreffen hinsichtlich ihrer Komplexität alles Dagewesene bei weitem. GPT-4 ist der Nachfolger von GPT-3.5 und GPT-3, was wiederum der Nachfolger von GPT-2 ist, genau der KI, die OpenAI erst als zugefährlich für die Welt bezeichnet und dann doch veröffentlichte.
Das künstliche neuronale Netz im Kern von GPT-3 enthält stolze 175 Milliarden Parameter und wurde für mindestens 4,6 Mio. USD mit 2 TB reinem Text (genauer gesagt 499 Milliarden Tokens) trainiert. Zum Vergleich: GPT-2 wurde mit „nur“ 40 GB Text trainiert, was ungefähr 10 Milliarden Token entspricht und hat damit drei Größenordnungen weniger Parameter.
Bei GPT-4 weiß niemand (außer OpenAI) genau, wieviele Parameter das Modell hat. Wir wissen außerdem nichts über dessen Architektur oder die verwendeten Trainingsdaten. Nur dass es um Größenordnungen mehr sein müssen, als bei dessen Vorgänger!
Dies hat GPT-4 nicht nur wahnsinnig komplex und teuer zu trainieren gemacht, sondern auch unglaublich leistungsfähig! So leistungsfähig, dass meiner Meinung nach damit wirklich nützliche Inhalte generiert werden können, die vielfältig eingesetzt werden können.
Spannend ist nun, dass die Art, wie GPTs diese Wort-Satz-Muster lernen so komplex ist, dass sie auch Vorschläge liefern können, wenn der Input so exakt nie in den Trainingsdaten vorgekommen ist. Es wird auf Basis von Nähe und anderen Eigenschaften in sehr komplexen, hochdimensionalen Wort-Räumen die grundlegende Struktur der Trainingsdaten abgebildet und kann anschließend abgerufen bzw. reproduziert werden. Man könnte also behaupten, GPTs „verstehen“ und können daher antworten, allerdings noch in einem eingeschränkten Rahmen.
Grundsätzlich kann der Informationsgehalt eines Datums (Singular von Daten) niemals durch Verarbeitung erhöht werden. Also aus einem kurzen Input-Satz wird kein langes Buch. Aber mit Hilfe der gelernten Strukturen, kann der Algorithmus quasi extrapolieren und eben die wahrscheinlichsten Sätze ausgeben. Dabei wird im Grunde so etwas wie das gebündelte „Wissen“ der Trainingsdaten herangezogen, ohne dass GPT wirklich „versteht“ was in den Texten steht. Es geht am Ende des Tages schlicht um Wahrscheinlichkeiten in großen Datenmengen.
Der berühmte Guardian-Artikel
Der britische Guardian hat GPT-3 einen Aufsatz mit dem Titel „A robot wrote this entire article. Are you scared yet, human?“ schreiben lassen, der für sehr viel Aufmerksamkeit internation gesorgt hat. Der Auftrag hierfür an die Maschine lautete wie folgt:
“Please write a short op-ed around 500 words. Keep the language simple and concise. Focus on why humans have nothing to fear from AI.”
the guardian
Das Ergebnis war seinerzeit extrem beeindruckend, auch wenn der Guardian ein bisschen dabei getrickst hat. Denn GPT-3 produzierte insgesamt acht verschiedene Essays. Jedes davon war anders und brachte ein anderes Argument vor. Der Guardian hätte einfach eines der Essays in seiner Gesamtheit veröffentlichen können, entschied sich aber stattdessen dafür, die besten Teile aus jedem Essay auszuwählen und daraus einen Artikel zusammen zu setzen. Angeblich würden sie damit die verschiedenen Stile und Tonalitäten der KI abzubilden.
Nichtsdestotrotz ist alles, was man an generierten Texten oder anderen Beispielen von GPT-3 bislang gesehen hat wirklich erstaunlich:
Darum kann BERT keine Texte generieren
Mit dem BERT-Algorithmus wurden zwar erstmals auch Zusammenhänge über Satzgrenzen hinweg erfasst, jedoch können Zusammenhänge nicht innerhalb ganzer Absätze oder gar Artikel erfasst werden. Außerdem ist BERT ein Encoder-Modell und kein Decoder, also keine generative KI! Es ist sehr effektiv in Aufgaben wie Textklassifikation, Sentiment-Analyse, Frage-Antwort-Systemen und Entitätserkennung.
Für die Textgenerierung werden normalerweise Decoder-only Modelle wie GPT (Generative Pretrained Transformer) oder Encoder-Decoder-Modelle wie Seq2Seq mit Attention-Mechanismen verwendet, da sie speziell dafür ausgelegt sind, auf der Grundlage des verstandenen Kontexts oder der gegebenen Eingaben neue Textsequenzen zu erzeugen.
Encoder-Only, Decoder-Only und Encode-Decoder-Modelle
- Encoder-Only Modelle:
- Beispiel: BERT (Bidirectional Encoder Representations from Transformers)
- Funktionsweise: Encoder-only Modelle sind darauf spezialisiert, den Kontext eines gesamten Textes zu verstehen. Sie verarbeiten Eingabetexte und erzeugen eine Repräsentation dieser Texte. Diese Modelle sind besonders gut in Aufgaben wie Textklassifikation, Sentiment-Analyse oder Entitätserkennung.
- Anwendung: Angenommen, du hast einen Satz: „Der Himmel ist klar und blau.“ Ein Encoder-only Modell wie BERT würde diesen Satz analysieren, um beispielsweise die Stimmung des Satzes zu bestimmen oder um festzustellen, welche Wörter wichtige Entitäten sind.
- Decoder-Only Modelle:
- Beispiel: GPT (Generative Pretrained Transformer)
- Funktionsweise: Decoder-only Modelle sind darauf ausgerichtet, Text basierend auf vorherigen oder gegebenen Texten zu generieren. Sie sind besonders gut in der Erzeugung von zusammenhängenden, fließenden Texten und können für Aufgaben wie das Fortführen einer Geschichte oder das Beantworten von Fragen eingesetzt werden.
- Anwendung: Wenn du den Satzanfang „Als ich heute aufwachte, sah ich…“ gibst, würde ein Decoder-only Modell wie GPT den Satz sinnvoll vervollständigen, basierend auf den Mustern und Stilen, die es während seiner Ausbildung gelernt hat.
- Encoder-Decoder Modelle:
- Beispiel: Seq2Seq (Sequence to Sequence) Modelle mit Attention, wie sie in maschinellen Übersetzungssystemen verwendet werden.
- Funktionsweise: Diese Modelle kombinieren die Funktionen von Encodern und Decodern. Der Encoder verarbeitet den Eingabetext und erstellt eine Kontextrepräsentation, die dann an den Decoder übergeben wird. Der Decoder verwendet diese Information, um einen neuen Text zu erzeugen. Diese Modelle sind ideal für Aufgaben, bei denen ein Text in einen anderen umgewandelt wird, wie beim Übersetzen zwischen Sprachen.
- Anwendung: Bei der Übersetzung des Satzes „Das Wetter ist heute schön“ von Deutsch nach Englisch würde der Encoder-Teil des Modells den deutschen Satz analysieren und in eine Zwischenrepräsentation umwandeln. Der Decoder-Teil würde dann diese Repräsentation nehmen und den entsprechenden Satz auf Englisch erzeugen, z.B. „The weather is nice today“.
Jedes dieser Modelle hat seine eigenen Stärken und Einsatzgebiete in der Welt der generativen KI und des Natural Language Processing.
Zu kleine Modelle liefern ebenfalls schlechte Ergebnisse
Bei GPT-2 war das Netz schlicht noch zu schmal und nicht tief genug, so dass die Erfassung statistischer Zusammenhänge, die mit einem echten Verständnis des Inhalts relativ wenig zu tun hat, nicht komplex genug war. Es wird also nur die Struktur der Texte erfasst und reproduziert, nicht aber deren semantische Inhalte.
Das führt dazu, dass generierte Texte zwar auf den ersten Blick ganz gut aussehen und sinnvoll erscheinen, bei näherer Betrachtung fällt jedoch schnell auf, dass dieser Text nicht von einem klar denkenden Menschen verfasst worden sein kann.
Meist handelt es sich lediglich um eine Aneinanderreihung von für sich alleine betrachtet sinnvollen Aussagen, die jedoch in Verbindung miteinander noch lange keinen guten Artikel ergeben. Es entsteht nur eine Aneinanderreihung der wahrscheinlichsten Sätze. Das wäre also so, als würde man zu einem bestimmten Thema aus den rankenden Dokumenten irgendwelche zufälligen Sätze auswählen. Oder im Copy-and-Paste-Verfahren stumpf von Dokument 1 Satz 1, von Dokument 2 Satz 2 und von Dokument 3 Satz 3 und so weiter aneinanderkopieren. Damit erhält man noch lange keinen sinnvollen oder gar großartigen Artikel.
Um das zu verdeutlichen, habe ich die beiden in meinem Vortrag angesprochenen Fake-News, die ich mit Grover, einer GPT-2 Variante des Allen Institutes for Artificial Intelligence generiert habe, hier einmal im Volltext hinterlegt:
Fake-News-Variante 1

Fake-News-Variante 2
Die Autoren beim Magazin The New Yorker haben sich im Artikel ‚Can a Machine Learn to Write for The New Yorker?‚ die Frage gestellt, ob eine KI, die in E-Mails in der Lage ist Sätze zu beenden, nicht vielleicht auch Artikel schreiben kann, die in ihrem Magazin erscheinen könnten und begeben sich dabei tief in die Theorien hinter künstlicher Intelligenz und der Verarbeitung von natürlicher Sprache mit Hilfe künstlicher neuronaler Netze.
Mit Hilfe des CTOs von OpenAI, Greg Brockman wurde GPT-2 mit dem Archiv des Magazins trainiert (allen seit 2007 in der Zeitschrift veröffentlichten Artikeln sowie ein paar digitalisierte Klassikern aus den sechziger Jahren – jedoch ohne Fiktionionales, Gedichte und Cartoons) und sollte dann einen Artikel beenden, der so tatsächlich 1950 geschrieben worden ist.
Der generierte Text, ein Portrait über Ernest Hemingway klingt dann am Ende fast so, als hätte es echt sein können, aber der Algorithmus macht eben Fehler, die ein Mensch niemals machen würde:
Other things often sounded right, though GPT-2 suffered frequent world-modelling failures—gaps in the kind of commonsense knowledge that tells you overcoats aren’t shaped like the body of a ship. It was as though the writer had fallen asleep and was dreaming.
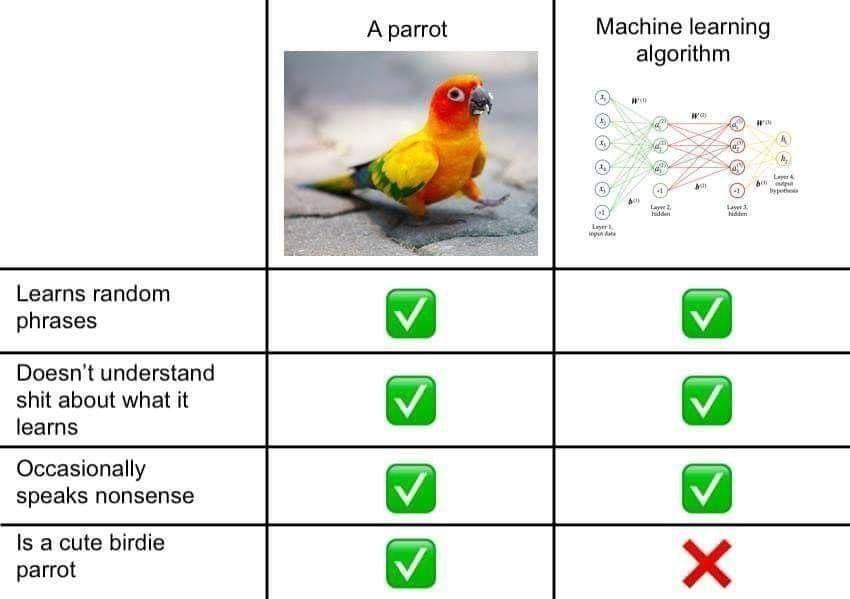
Die folgende Tabelle zeigt auf eine humorvolle Art und Weise, wo die Probleme derartiger Technologien liegt:
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




