Wahrscheinlich hast du schon einmal diese Grafik gesehen, die die Anzahl der Parameter von GPT-4 im Vergleich zu dessen Vorgänger GPT-3 anschaulich machen soll. Für ein paar Tage war das die am häufigsten geteilte Grafik bei LinkedIn überhaupt:
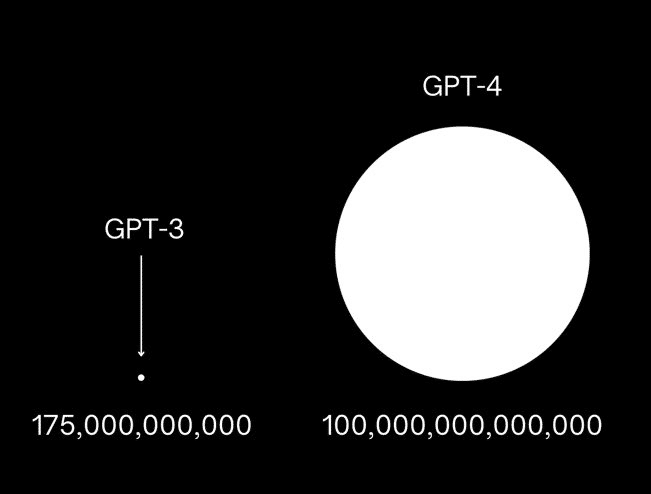
Leider handelt es sich hierbei um kompletten Bullshit!
Der Twitter-Nutzer AiBreakfast erstellte diese unglaublich erfolgreiche Grafik auf Basis von falschen Informationen. An vielen Stellen wird die Anzahl der Parameter von GPT-4 mit „100 trillion“ angegeben. Die amerikanische „trillion“ entspricht dabei unserer Billion, also 100 Billionen Parameter. Eine 1 mit 12 Nullen. Also 100.000 Milliarden oder ausgeschrieben 100.000.000.000.000 Parameter.
Dabei handelt es sich um eine der populärsten Falschinformation rund um das neue GPT-4 Sprachmodell.
Diese Zahl stammt aus einem Artikel von Wired vom August 2021, in dem erstmals über die Eigenschaften eines GPT-3-Nachfolgers gemunkelt wurde. Darin sagt Andrew Feldman, der CEO von Cerebras, einem Unternehmen das Supercomputer für das Training von KI-Modellen baut, in einem Interview mit dem Magazin Wired „From talking to OpenAI, GPT-4 will be about 100 trillion parameters“.

Schaut man sich jedoch den nächsten Satz im selben Interview an, wird klar, dass Feldman nicht vom selben GPT-4 sprechen kann, das OpenAI im März diesen Jahres veröffentlicht hat: „That won’t be ready for several years.”
Aber eigentlich ist es noch viel schlimmer, denn Feldman, CEO eines Startups mit einer Milliarden-Bewertung redet hier absoluten Bullshit! Niemand bei OpenAI hat jemals etwas in dieser Richtung gesagt!
In Wirklichkeit stammt die Zahl von „100 trillion“ aus einer Präsentation von Lex Fridman, in der er berechnet, was eine künftige Version von GPT mit so vielen Parameter wie das Gehirn Synapsen haben für die Trainingskosten bedeuten würde. Das menschliche Gehirn liefert dann mit seinen etwa 100 Billionen Synapsen die Vorlage für die Annahme eines zukünftigten, hypothetischen Modells mit 100 Billionen Parametern.
Das erklärte er später in seinem Interview mit dem OpenAI CEO Sam Altmann. Hier ein kurzer Ausschnitt, in dem die beiden über das Missverständnis sprechen:
Spätestens durch die Reaktion von Sam Altmann auf diese Zahl wird klar, dass auch Feldman die 100 Billionen definitiv nicht von OpenAI haben kann. Er hat wahrscheinlich das Video von Friedman gesehen und da etwas verwechselt. Vielleicht wollte er es auch so darstellen, immerhin konstruiert und vertreibt seine Firma Spezial-CPUs, die für das Training extrem komplexer Modelle benötigt werden.
Doch wie es im Journalismus so läuft, zitieren meist alle von derselben Quelle, ohne diese auf ihren Wahrheitsgehalt hin zu überprüfen.
Der erste, der diese Zahl in Frage gestellt hat, ist der KI-Experte Cobus Greyling. Dieser stellte in seinem Artikel bei Medium die Frage, ob diese Erwartung an GPT-4s Größe überhaupt realistisch sind.
Sein Beitrag sollte eigentlich den Hype rund um das nächste Sprachmodell stoppen, denn er betrachtete historische Skalierung großer Sprachmodelle und kommt zum Schluss, dass GPT-4 sehr viel wahrscheinlicher „1 Trillion“, also 1 Billion Parameter haben dürfte, als „100 Trillion“.
Diese Annahme trifft Greyling schlicht und einfach, weil die größten Konkurrenzmodelle, wie Googles PaLM und MT-NLG etwa 500 Milliarden Parameter haben und GPT-4 mit 1 Billion doppelt so groß wäre. Mit 100 Billionen Parametern wäre GPT-4 gleich 200 mal größer, als das größte Modell der Konkurrenz, was in der Tat wenig realistisch ist.

Doch anstatt die genannte Anzahl der Parameter in Frage zu stellen, führte dieser Artikel zu einer weiteren Welle der Verbreitung von Fehlinformationen. So behauptet der Journalist Reed Albergotti in seinem Artikel Ende März „The latest language model, GPT-4, has 1 trillion parameters“ ohne dabei irgendeine Quelle zu nennen. Was auf Wikipedia jedoch so dargestellt wird, als hätte er behauptet, er habe mit „acht Personen, die mit der Insider-Geschichte vertraut sind“, innerhalb von OpenAI gesprochen und herausgefunden, dass GPT-4 eine Billion Parameter hätte.
So schnell wird aus einer groben Einschätzung ein Faktum. Wirklich erschreckend!
Doch wieviele Parameter hat GPT-4 denn nun?
Die Wahrheit ist, dass OpenAI bis heute keinerlei nähere Informationen zu GPT-4s Aufbau veröffentlich hat. Es ist weder bekannt, inwieweit sich die Architekt im Vergleich zu dessen Vorgänger GPT-3 verändert hat, noch wie viele Parameter genau das Modell hat.
Wir wissen noch nicht einmal, mit welchen Trainingsdaten GPT-4 trainiert wurde! Bei GPT-3 wurden diese Informationen noch in einem Forschungspapier veröffentlicht, doch die zunehmende Kommerzialisierung der Sprachmodelle und die zunehmende Konkurrenz durch Google, Meta, Aleph Alpha und Co. führt jedoch dazu, dass man bei OpenAI nicht mehr so detailliert über die neuesten Fortschritte spricht.
Es lässt sich somit nur abschätzen, wieviele Parameter GPT-4 ungefähr haben könnte!
Der technische Bericht zu GPT-4 enthält zwar keine Angaben zur Größe des Modells, zur Architektur oder zur Hardware, die beim Training oder bei der Inferenz verwendet wurde, er beschreibt jedoch, dass das Modell zunächst mit einer Kombination aus überwachtem Lernen auf einem großen Datensatz und anschließendem Verstärkungslernen unter Verwendung von menschlichem und KI-Feedback trainiert wurde. Dieses nachträgliche Fine-Tuning ist für die Leistungsfähigkeit großer Sprachmodells tatsächlich wichtiger, als die pure Anzahl der Parameter. Das konnte man bereits bei Stanfords Alpaca wunderbar sehen, das auf Metas LLaMA-Modell basiert und mittels Feedback von GPT-4 nachtrainiert wurde. Mit nur 7 Milliarden Parametern, also einem 25tel der Größe von GPT-3 erreicht Alpaca vergleichbare Leistungen bei diversen Aufgaben.
Gräbt man noch etwas tiefer findet man im WIRED Interview noch die Angabe von Sam Altman, dass die Kosten für das Training von GPT-4 mehr als 100 Millionen Dollar betrugen. Im Vergleich zu den (geschätzten) 4,6 Millionen von GPT-3 also eine verzwanzigfachung des Rechenaufwands, was wiederum nicht unmittelbar auf 20-mal so viele Parameter in GPT-4 schließen lässt.
Update: Geheimnisse hinter GPT-4 offenbar gelüftet!
GPT-4 war das am meisten erwartete KI-Modell der Geschichte. Aber als OpenAI es im März veröffentlichte, verrieten sie uns nichts über seine Größe, seine Trainingsdaten, seine interne Struktur oder wie sie es trainiert und gebaut hatten. GPT-4 ist bis heute eine echte Blackbox.
Wie sich gerade heraus stellt, wurden diese wichtigen Details nicht verschwiegen, weil das Modell zu innovativ oder die Architektur zu ausgeklügelt war, um sie mit der Konkurrenz zu teilen. Das genaue Gegenteil scheint der Fall zu sein, wenn man den jüngsten Gerüchten Glauben schenkt:
GPT-4 weder technisch noch wissenschaftlich ein Durchbruch!
Das macht GPT-4 nicht schlechter – schließlich ist GPT-4 das leistungsstärkste Sprachmodell, das es gibt – nur irgendwie etwas enttäuschend. Und so garnicht das, was man nach 3 Jahren des Wartens erwartet hatte.
Diese Nachricht, die übrigens noch nicht offiziell bestätigt wurde, enthüllt wichtige Informationen über GPT-4 und OpenAI und wirft Fragen über den wahren Stand der KI und ihre Zukunft auf:
GPT-4: Eine Mischung kleinerer Modelle
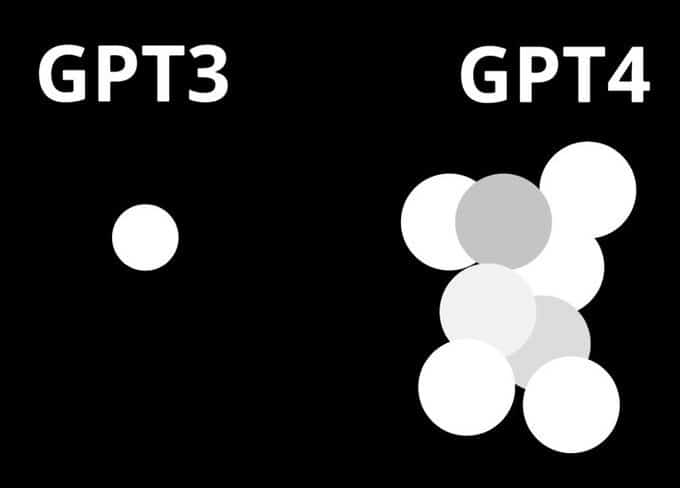
Am 20. Juni ließ George Hotz, Gründer des selbstfahrenden Start-ups Comma.ai, bei Twitter durchsickern, dass GPT-4 kein einzelnes, monolithisches, dichtes Modell (wie GPT-3 und GPT-3.5) ist, sondern eine Mischung aus 8 x 220 Milliarden Parametermodellen. George Hotz ist auch bekannt unter den Pseudonymen geohot und erreichte durch seine Exploits für das Apple iPhone, die PlayStation 3 und das iPad einen hohen Bekanntheitsgrad in der Hackerszene. Später am selben Tag bestätigte Soumith Chintala, Mitbegründer von PyTorch und aktuelle KI-Forscher bei Meta, das Leck in einem Tweet. Nur einen Tag zuvor hatte Mikhail Parakhin, Chef von Microsofts Bings KI-Integrationsprojekts, dies ebenfalls angedeutet.
Bei GPT-4 handelt es sich demnach nicht um ein großes Modell mit mehr als einer Billionen Parametern, sondern um acht kleinere, geschickt zusammengesetzte Modelle. Das „Mischung aus Experten“-Paradigma, die OpenAI angeblich für dieses „Hydra“-Modell verwendet hat, ist weder neu, noch wurde sie von ihnen erfunden.
Zwei Einschränkungen bzw. Vorbehalte:
Erstens: Es ist ein Gerücht. Die expliziten Quellen (Hotz und Chintala) sind solide, aber keine Mitarbeiter von OpenAI. Parakhin hat eine leitende Position bei Microsoft, hat dies aber nie explizit bestätigt. Aus diesen Gründen ist das Gerücht mit Vorsicht zu genießen. Die Geschichte ist aber durchaus plausibel.
Zweitens: Ehre, wem Ehre gebührt. Der GPT-4 ist so beeindruckend, wie seine Benutzer sagen. Daran ändern auch die Details des inneren Aufbaus nichts. Wenn es funktioniert, dann funktioniert es. Dabei spielt es keine Rolle, ob es sich um ein einzelnes Modell oder um acht miteinander verbundene Modelle handelt. Seine Leistung und seine Fähigkeit, Aufgaben zu schreiben und zu programmieren, sind legitim. Die Informationen stammen aus einem Artikel von Alberto Romero und sind keine Kritik an GPT-4 – nur eine Warnung, dass wir vielleicht unsere Erwartungen verändern sollten.
Die Geheimniskrämerei um GPT-4
Alberto lobt in seinem Beitrag OpenAI explizit dafür, wie meisterhaft sie mit den unangemessen hohen Erwartungen um GPT-4 umgegangen sind, indem sie die weniger befriedigenden Aspekte des Modells verheimlicht haben und gleichzeitig an der Spitze der Diskussion geblieben sind.
Als Connie Loizos von StrictlyVC im Januar die lächerlichen 100-Billionen-GPT-4-Diagramme erwähnte, die auf Twitter die Runde machten, antwortete Altman ihr, dass „die Leute darum betteln, enttäuscht zu werden, und das werden sie auch“. Er wusste, dass der GPT-4, der im Sommer 2022 ausläuft, die Erwartungen der Menschen nicht erfüllen würde.
Aber er wollte den fast mystischen Ruf von OpenAI nicht zerstören. Also versteckte man GPT-4 vor der Öffentlichkeit, was seine geheimnisvolle Aura noch verstärkte.
Zu diesem Zeitpunkt hatte OpenAI seinen Status mit ChatGPT bereits gefestigt. In den Augen der Mehrheit waren sie auf diesem Gebiet führend (trotz Googles längerer und umfangreicherer Forschungs- und Entwicklungsgeschichte). Daher konnten sie nicht explizit zugeben, dass GPT-4 nicht der erwartete Durchbruch – und der große Sprung von GPT-3 – war, den sich die Leute erhofft hatten.
Daher konzentrierten sie sich auf Anspielungen und Andeutungen, dass es wirklich leistungsfähig sei (z.B. Funken von allgemeiner Intelligenz, Superintelligenz ist nah, usw.) und verteidigten ihre Entscheidung, die Spezifikationen von GPT-4 nicht zu veröffentlichen, mit dem Hinweis auf den erhöhten Wettbewerbsdruck, wie Ilya Sutskever gegenüber The Verge erklärte.
Vor diesem Hintergrund lautete die gängige Interpretation der Geheimhaltung von OpenAI in etwa so „Sie geben die Spezifikationen nicht preis, weil sie es sich aus Gründen des wirtschaftlichen Überlebens und der Sicherheit nicht leisten können, von Google oder Open-Source-Initiativen kopiert zu werden. Außerdem deutet die SOTA-Performance von GPT-4 darauf hin, dass es sich bei der Architektur um eine wissenschaftliche Meisterleistung handeln muss.“
OpenAI hat bekommen, was es wollte. Altman war ehrlich – GPT-4 wäre eine Enttäuschung gewesen – aber gleichzeitig suggerierten die unterschwelligen Signale etwas anderes: GPT-4 ist magisch. Und die Leute glaubten es.
In gewisser Weise ist es magisch. Wir haben es alle in Aktion gesehen. Es ist nur nicht das, was die meisten Menschen als revolutionäre Errungenschaft wahrnehmen würden. Es scheint nur ein alter Trick zu sein, der neu erfunden wurde. Die Kombination mehrerer Expertenmodelle zu einem einzigen, wobei jeder Experte auf unterschiedliche Bereiche, Aufgaben oder Daten spezialisiert ist, wurde erstmals 2021 erfolgreich eingesetzt. Vor zwei Jahren. Wer hat das gemacht? Du hast es erraten: Google-Ingenieure (einige von ihnen, wie William Fedus und Trevor Cai, wurden später von OpenAI eingestellt).
OpenAI hat sicherlich noch mehr technischen Einfallsreichtum eingebracht (sonst hätte Google sein eigenes GPT-4 oder ein besseres), aber der Schlüssel zur absoluten Dominanz des Modells in den Benchmarks ist einfach, dass es nicht nur ein Modell ist, sondern acht!
Ja, GPT-4 ist magisch, aber es ist eine clevere Mischung aus geschickter Täuschung und geschickter Manipulation. Und der Trick ist nur ein Remake einer bekannten Technik.
Die 3 Ziele, die OpenAI mit dem Verstecken von GPT-4 erreicht hat
Erstens haben sie die Phantasie der Menschen angeregt. Obwohl Skeptiker dies als unwissenschaftliche Praxis ansahen, heizte es die Spekulationen über die Leistungsfähigkeit des Modells an. Dies wiederum ermöglichte es ihnen, ihr bevorzugtes Narrativ – AGI und die Notwendigkeit, dafür zu planen – zu etablieren und die Regierung davon zu überzeugen, dass Sicherheitsanforderungen (vor allem für andere) und Regulierung (im Einklang mit ihren Zielen) an erster Stelle stehen. Die Illusion war komplett: Der GPT-4 hatte ein glänzendes Äußeres, also musste er auch innen glänzend sein – und glänzend kann gefährlich sein.
Zweitens haben sie Open-Source-Initiativen und Konkurrenten wie Google oder Anthropic effektiv daran gehindert, die Techniken zu kopieren, die sie angeblich erfunden oder entdeckt hatten. Aber OpenAI hatte keinen Burggraben in GPT-4. Metas LLaMA oder Googles LaMDA sind nicht in der Lage, mit GPT-4 zu konkurrieren, aber vielleicht können es 8 miteinander verbundene LLaMAs – die Leute verglichen Äpfel mit Birnen ohne es zu wissen.
Schließlich verbargen sie die Wahrheit, dass GPT-4 in Wirklichkeit kein großer Durchbruch in der KI war, und verhinderten so, dass Zeugen, Außenstehende und Nutzer den Glauben an den scheinbar rasanten Fortschritt auf diesem Gebiet verloren. Wenn man es genau nimmt, ist GPT-4 das Ergebnis der Tatsache, dass man einerseits genug Geld und GPUs hatte, um acht GPT-3.5-Modelle zu trainieren und laufen zu lassen, und andererseits die Dreistigkeit besaß, eine alte Technologie, die von einer anderen Firma erfunden worden war, zu klauen, ohne es jemandem zu sagen.
GPT-4 ist eine Spitzenleistung in Sachen Marketing.
Alberto Romero fügt seinem Beitrag noch folgenden letzten Gedanken hinzu:
Vielleicht sind OpenAI – und der ganzen Branche – die Ideen ausgegangen, wie Hotz meint. Vielleicht schreitet die KI nicht so schnell von Meilenstein zu Meilenstein voran, wie Unternehmen, Medien, Vermarkter und arXiv glauben machen wollen. Vielleicht ist GPT-4 kein so großer Sprung von GPT-3, wie er hätte sein sollen.
Ein Gerücht bleibt ein Gerücht, bis wir eine offizielle Version erhalten. Es ist jedoch schwierig, die Plausibilität der Geschichte zu bestreiten. Abgesehen vom Wert der Quellen ist sie im Großen und Ganzen stimmig. Aus diesem Grund räume ich ihr einen hohen Grad an Glaubwürdigkeit ein.
Abschließend zitiert er die Schlussfolgerung von Hotz: „Wenn eine Firma geheimnisvoll ist, dann deshalb, weil sie etwas verbirgt, das nicht so cool ist.“
Vielleicht ist GPT-4 also doch nicht so cool.
Weitere Details zur Architektur von GPT-4
Es gibt Neuigkeiten bezüglich der GPT-4-Architektur von OpenAI: Ein aktueller Bericht von SemiAnalysis bringt Licht ins Dunkel und zeigt: Das Geheimnis um GPT-4 liegt weniger in einer existenziellen Bedrohung für die Menschheit, sondern vielmehr in der Tatsache, dass das Geschaffene replizierbar ist. OpenAI hat die Details zu GPT-4 offenbar versucht geheim zu halten, damit niemand das Modell nachbaut, denn im Kern handelt es sich um die Kombination bekannter Techniken, die jedoch sehr intelligenz genutzt und geschickt kombiniert wurden. Die Informationen wurden von Yam Peleg auf Twitter geleaked, mittlerweile jedoch bereits wieder gelöscht.
Hier sind die wichtigsten Punkte zusammengefasst:
- Die Größe von GPT-4 ist beeindruckend: Mit rund 1,8 Billionen Parametern in 120 Schichten ist es offenbar mehr als zehnmal so groß wie sein Vorgänger, GPT-3. Diese Aussage gilt als gesichert.
- Im Kern des Systems steht, wie schon im letzten Leak behauptet, das Prinzip des „Mixture of Experts“ (MoE). Bei GPT-4 kommen jedoch offenbar 16 (statt nur 8) solcher Experten zum Einsatz, jeder mit rund 111 Milliarden Parametern.
- Pro Vorwärtsdurchlauf werden jedoch lediglich zwei dieser Experten genutzt, was dazu beiträgt, die Kosten überschaubar zu halten. Jede Vorwärtsinferenz (Erzeugung von 1 Token) benutzt „nur“ 280 Milliarden Parameter und damit etwa 560 TFLOPs. Dies steht im Gegensatz zu den 1,8 Billionen Parametern und rund 3.700 FLOP, die für einen Vorwärtsdurchlauf eines rein dichten Modells erforderlich wären. Die Kosten für die Inferenz von GPT-4 sind damit etwa dreimal höher als beim 175B-Parameter-Modell Davinci von GPT-3. Dies ist auf die größeren erforderlichen Cluster und die geringere Auslastung zurückzuführen.
- Dabei entscheidet das Modell, je nach Aufgabe, welche dieser Experten wahrscheinlich am geeignetsten sind. Während in der Literatur viel über fortschrittliche Routing-Algorithmen für die Auswahl der Experten gesprochen wird, an die jeder Token weitergeleitet werden soll, ist der von OpenAl für das aktuelle GPT-4-Modell angeblich recht einfach. Es gibt ungefähr 55 Milliarden gemeinsame Parameter für die Aufmerksamkeit.
- Für das Training von GPT-4 wurden beeindruckende 13 Billionen Token genutzt, darunter sowohl Text- als auch Code-basierte Daten (unter anderem CommonCrawl und RefinedWeb). Es gibt außerdem Spekulationen über weitere Datenquellen wie Twitter, Reddit, YouTube und eine umfangreiche Sammlung von Lehrbüchern. Zum Vergleich: Bei GPT-3 waren es lediglich 300 Milliarden Token, also sind die Trainingsdaten mehr als 40 mal so umfangreich bei GPT-4. Zusätzlich wurden Millionen von Zeilen an Anweisungen von ScaleAI und internen Quellen zur Feinabstimmung des Modells verwendet.
- Die Trainingskosten für GPT-4 belaufen sich auf etwa 63 Millionen US-Dollar, wenn man 1$ je Trainingsstunde auf einem A100 annimmt. Dieser Betrag berücksichtigt sowohl die notwendige Rechenleistung als auch die Dauer des Trainingsprozesses.
- Eine besonders interessante Neuheit bei GPT-4 ist ein Bildverarbeitungs-Encoder, der autonome Agenten unterstützen kann, die Webseiten lesen und Bilder und Videos transkribieren. Diese Architektur ist ähnlich der von Flamingo von Deepmind und wurde mit zusätzlichen ~2 Billionen Token fein abgestimmt. Wer etwas mehr darüber erfahren will, sollte diesen Artikel lesen. Aktuell steht diese Funktion jedoch ausschließlich einigen wenigen Partnern zur Verfügung. Das einzige öffentliche Projekt, das mir bekannt ist, ist die Be my eyes app, die Menschen mit Blindheit und Sehbehinderung ermöglichen soll, besser in unbekannten Umgebungen zurecht zu kommen. Das YouTube-Video dazu hat bei mir zu einem echten Gänsehautmoment gesorgt:
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




