Für meinen aktuell laufenden Onlinekurs „The Future of Search“ entwickle ich gerade ein kleines Tool, mit dem man gezielt die Relevanz von Dokumenten zu Suchanfragen messen kann, um gezielter für die kommenden „AI Overviews“ oder „Search Generative Experience“ optimieren zu können. Bei meinen Recherchen bin ich auf etwas unglaublich spannendes gestoßen…
Das Unternehmen hat seine Suchtechnologie, die bis dato als „Enterprise Search“ vermarktet wurde und auf den Kernbestandteilen der Google Suche basiert, für alle über die Vertex AI API verfügbar gemacht. Diese nutzt unter anderem das proprietäre RankBrain-System, ein einzigartiges Text-Embedding-Modell sowie ein fortgeschrittenes neuronales Matching-System, das bislang nur von ausgewählten Testkunden ausprobiert werden konnte.
Diese Entwicklung eröffnet aus meiner Sicht vollkommen neue Perspektiven für SEO-Experten & -Expertinnen sowie KI-Enthusiasten & -Enthusiastinnen. Insbesondere mit Blick auf die SGE (Search Generative Experience) und Googles AI Overviews bekommt dieser Release, den wahrscheinlich die meisten nicht einmal mitbekommen haben, aus meiner Sicht eine vollkommen neue Bedeutung.
Zum ersten mal ist es möglich, das Ranking von Dokumenten, alleine auf Basis deren Relevanz bei Google zu erforschen, ohne dass andere Rankingfaktoren dieses Bild verzerren. Und das beste: Vertex AI Search kann noch mehr!
Kai Spriestersbach
Was ist Vertex AI Search?
Vertex AI Search ist eine sofort einsatzbereite Suchmaschine, die von der Vertex AI-Plattform von Google Cloud bereitgestellt wird. Damit können Unternehmen schnell auf generativer KI basierende Suchmaschinen für Kunden und Mitarbeiter erstellen. Wenn Sie die Qualität der Suche auf Ihren Websites verbessern möchten oder Ihre Mitarbeiter interne Daten leichter finden sollen, können Sie über Vertex AI Search ganz einfach Suchmaschinen einrichten, die Ihren Zielen entsprechen und gleichzeitig Zugriffssteuerung, Datenschutz und Datenhoheit unterstützen.
Vertex AI Search baut auf einer Vielzahl von Google-Suchtechnologien auf, darunter die semantische Suche. Durch Natural Language Processing sowie Machine Learning lassen sich so relevantere Ergebnisse als bei herkömmlichen, auf Suchbegriffen basierenden Suchverfahren bereitstellen, weil anhand der Suchanfrage des Nutzers Beziehungen innerhalb des Inhalts sowie die eigentliche Absicht erkannt werden.
Der wirklich interessante Teil ist allerdings aus meiner Sicht:
Darüber hinaus baut Vertex AI Search auf die Google-Erfahrung zum Suchverhalten der Nutzer auf und berücksichtigt bei der Reihenfolge der angezeigten Ergebnisse die Relevanz von Inhalten.
Denn damit verrät Google quasi, dass mehr als nur reine Texte in das Modell einfließen. Insbesondere dieser Umstand, also dass Daten zum Nutzerverhalten der Google Suche verwendet werden, um die Ergebnisse von Rankbrain zu verbessern, macht die Technologie aus meiner Sicht extrem interessant für SEOs, im Gegensatz zu klassischen Text-Embeddings von OpenAI & Co.
Was ist Google RankBrain?
RankBrain, eingeführt im Jahr 2015, ist ein auf maschinellem Lernen basierendes System, das Google nutzt, um Suchanfragen zu verstehen und relevante Ergebnisse zu liefern. Über Jahre hinweg haben SEOs darüber gerätselt, was sich hinter dieser Technologie verbergen könnte. Google spricht selbst von einem „Deep-Learning-Rankingsystem“.
Was genau sich dahinter verbirgt, können wir uns nun selbst anschauen, denn Googles Cloud Dienst „Vertex AI Search“ nutzt dieselben RankBrain- und neuronalen Matching-Prozesse, um Abfrage- und Dokumenteneinbettungsvektoren zu generieren, die semantische Beziehungen abbilden und eine semantische Suche in Google-Qualität ermöglichen.
Im Grunde handelt es sich also um eine semantische Suche, die mit Text-Embeddings arbeitet, vergleichbar mit denen anderer Anbieter, wie beispielsweise OpenAI, nur mit dem Vorteil, dass dieses mit Nutzerdaten aus echten Suchvorgängen bei Google optimiert wurde.
Vertex AI Search ist optimiert für RAG
Der Hauptanwendungsbereich für diese Technologie ist natürlich die Retrieval-Augmented-Generation, kurz RAG. Beim RAG-Pattern kombiniert man große Sprachmodelle (LLMs) mit einem Informationsabruf aus externen Quellen, um einige der größten Einschränkungen von LLMs zu überwinden. Insbesondere der begrenzten Wissensbasis aufgrund des Trainingsdatensatzes, dem Mangel an relevantem Kontext aus Unternehmensdaten sowie veralteten Informationen im Sprachmodell lassen sich damit begegnen.
RAG heißt im Grunde, dass die KI eine Suchmaschine als Werkzeug benutzt, um Fragen besser beantworten zu können.
LLMs sind zwar intelligent genug, um Fragen zu verstehen und diese korrekt zu beantworten, wenn man ihnen die dazu notwendigen Informationen mitliefert, aber sie können ihre Leistung nicht voll ausschöpfen, wenn die Suche nicht die richtigen Dokumente findet, in denen die notwendigen Informationen stehen!
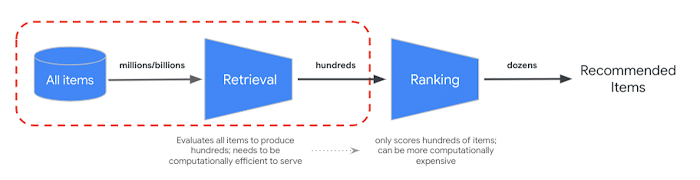
Seit dem RAG-basierte Ansätze in KI-Tools und Suchmaschinen wie perplexity oder auch ChatGPT Einzug halten, lässt sich gut nachvollziehen, dass die Effizienz eines RAG-Systems nahezu vollständig von der Suchqualität des Backend-Retrievalsystems, also der Suchmaschine dahinter abhängt und hier hat Google zweifelsohne die besten Daten.
In den letzten Monaten haben KI-Forscher und -Entwickler zahlreiche RAG-Technologien erforscht, darunter Text Chunking, Query Expansion, Hybrid Search, Knowledge Graphen, Reranking und andere. Aber fest steht: Ein LLM braucht die richtigen Daten, damit es keine Dinge erfinden muss, und du brauchst die beste Suchtechnologie, um die besten Daten zu bekommen.
Die semantische Suche mittels Deep Learning ist heutzutage für die meisten Suchmaschinen unverzichtbar geworden. Sie ermöglicht es Entwicklern, Systeme zu erstellen, die den Sinn von Suchanfragen verstehen können, anstatt nur nach Schlüsselwörtern zu suchen. Doch die meisten RAG-Systeme verwenden relativ einfache Ähnlichkeitssuchen in Vektordatenbanken, meist auf Basis der Text-Embeddings von Suchanfrage und Dokumenten-Chunks um Informationen zu finden. Dies führt jedoch oft zu qualitativ minderwertigen und irrelevanten Ergebnissen, insbesondere bei komplexeren Fragestellungen und Fachthemen.
Exkurs: Matching-Verfahren im RAG
Es gibt verschiedene Methoden, um die Ähnlichkeit zwischen zwei Vektoren zu berechnen, die in zahlreichen Anwendungen in der Künstlichen Intelligenz zum Einsatz kommen, zum Beispiel um zu erkennen, wie ähnlich sich zwei Sätze sind.
Die übliche Methode dafür ist die Cosine Similarity, zu Deutsch Kosinus-Ähnlichkeit. Sie hat aber einen Nachteil: Wenn zwei Vektoren sehr ähnlich sind (also fast in die gleiche Richtung zeigen), kann sie die kleinen Unterschiede nicht gut erfassen.
Google hat daher in einem Forschungspapier eine verbesserte Methode vorgeschlagen. Diese nennt sich Angular Distance (Winkelabstand). Sie kann auch bei sehr ähnlichen Vektoren die feinen Unterschiede besser erkennen.
Der Hauptunterschied ist, dass die Kosinus-Ähnlichkeit bei sehr ähnlichen Vektoren fast immer den Wert 1 ausgibt. Zudem ist die Kosinus-Ähnlichkeit beispielsweise effektiv bei hochdimensionalen Räumen, die typisch für Textanalysen sind, kann bei sehr kurzen Dokumenten oder Anfragen jedoch ziemlich unzuverlässig sein.
Die Angular Distance differenziert hier stärker und gibt unterschiedlichere Werte aus und ist insgesamt robuster bei kurzen Texten. Es ist also ein bisschen so, als ob man eine Lupe benutzt, um feine Unterschiede besser zu sehen. Das macht die Angular Distance gerade im Vergleich von Suchanfragen mit Dokumenten-Chunks in vielen Fällen genauer und nützlicher, allerdings auch rechenintensiver und weniger effizient bei hochdimensionalen Embedding-Vektoren. Für das Matching komplexer Suchanfragen mit längeren Dokumentenvektoren ist daher die Cosine Similarity oft die beste Wahl.
Es noch weitere Methoden, die ähnliche Verbesserungen bringen können. Die Wahl der besten Methode hängt vom konkreten Anwendungsfall ab. In der Regel findet zudem eine Vorverarbeitung der Texte (z.B. Stemming, Stopword-Entfernung) statt und es werden moderne Embedding-Techniken mit klassischen Relevanzkriterien (z.B. TF-IDF, BM25) kombiniert.
Semantische Suche ist mehr als nur Ähnlichkeitssuche von Texten
In wissenschaftlichen Publikationen und theoretischen Demonstration ist diese einfache Ähnlichkeitssuche sehr effektiv, da die Datensätze Millionen von Frage-Antwort-Paaren enthalten. In vielen realen RAG-Szenarien gibt es jedoch keine vorgefertigten Frage-Antwort- oder Anfrage-Kandidaten-Paare. Daher ist es wichtig, dass ein KI-Modell die Beziehung zwischen Anfragen und entsprechenden Antworten lernen und vorhersagen kann, um eine qualitativ hochwertige semantische Suche zu ermöglichen.
Google Search begann 2015 mit der Einführung der semantischen Suche, insbesondere durch das Deep-Learning-Rankingsystem RankBrain. Kurz darauf folgte das neuronale Matching, um die Genauigkeit der Dokumentensuche zu verbessern. Neuronales Matching ermöglicht es einer Suchmaschine, die Beziehungen zwischen den Absichten einer Anfrage und hochrelevanten Dokumenten zu erlernen. So kann die Suchmaschine den Kontext einer Anfrage erkennen, anstatt nur nach Ähnlichkeiten zu suchen.
Googles Vertex AI Search ist extrem spannend für SEOs, denn diese besondere Art des maschinellen Lernens hinsichtlich der Relevanz von Suchanfragen zu Dokumenten, genannt Rankbrain, bietet kein anderes Embedding-Modell.
Kai Spriestersbach
Neuronales Matching lernt die Beziehungen zwischen Anfragen und Dokumenten
Vertex AI Search nutzt tatsächlich die gleichen RankBrain- und neuronalen Matching-Prozesse, um Anfrage- und Dokument-Embeddings zu erzeugen, wie Googles Suche. Diese Vektoren bilden semantische Beziehungen ab und ermöglichen eine semantische Suche in Google-Qualität.
Über den Parameter task_type wird also der Anwendungszweck der Embeddings spezifiziert, um dem Modell zu helfen, Einbettungen mit höherer Qualität zu erstellen und diese Liste ist extrem interessant!
Es gibt sowohl Werte für Suchanfragen, als auch Dokumente einer Suche, sowie Texte für eine semantische Textähnlichkeit (Semantic Textual Similarity, STS). Andere NLP-Tasks wie Klassifizierung, Clustering und sogar die Beantwortung von Fragen werden offenbar jeweils mit speziell optimierten Embeddings versehen. Und sogar zur Faktenüberprüfung gibt es eigene Embeddings!
Das bietet kein anderer Anbieter!
Kai Spriestersbach
Anstatt selbst einen Weg zu finden, die Lücke zwischen Fragen und Antworten in einem RAG-System zu schließen, können Entwickler:innen ganz einfach die Vorteile der semantischen Suchtechnologie nutzen, die von Milliarden von Nutzer:innen über viele Jahre getestet wurde. Mit Vertex AI Search bietet Google nun eine vollständig verwaltete Plattform, die dieselben RankBrain- und Neural Matching-Prozesse nutzt, die Google Search seit Jahren einsetzt und die von Milliarden von Nutzern über viele Jahre hinweg trainiert und erprobt wurde.
Google ist führend bei semantischer Suche
Entgegen der weitverbreiteten Meinung ist die semantische Suche jedoch keine neue Erfindung, die erst mit dem Aufkommen von großen Sprachmodellen populär wurde. Tatsächlich ist sie das Ergebnis jahrelanger Forschung und Entwicklung.
Google war hier schon früh Vorreiter und traf bereits 2013 die strategische Entscheidung, in die Entwicklung eigener KI-Prozessoren zu investieren – den sogenannten Tensor Processing Units (TPUs). Diese TPUs wurden speziell dafür konzipiert, die nötige Rechenleistung für maschinelles Lernen und KI-Anwendungen bereitzustellen. Ihr Ursprung liegt laut Google jedoch in dem Ziel, das für eine praxistaugliche semantische Suche erforderliche Deep Learning zu ermöglichen.
Der erste TPU wurde 2015 in die Produktionsinfrastruktur von Google Search integriert. Diese erhebliche Investition hat dazu beigetragen, Kosten und Latenzzeiten zu reduzieren und so eine hochwertige semantische Suche für Milliarden von Nutzern zu realisieren. Google hat über Jahre hinweg in die Entwicklung leistungsfähiger Suchtechnologien investiert. So verarbeitet Google Search semantische Suchen mithilfe von ScaNN, einer der größten und schnellsten Vektorsuch-Infrastrukturen weltweit.
ScaNN kommt nicht nur bei Google Search zum Einsatz, sondern auch in vielen anderen Google-Diensten. Es findet blitzschnell relevante Dokumente und Inhalte, um Nutzern in Sekundenschnelle die benötigten Informationen zu liefern. Laut Benchmarks gehört ScaNN zu den führenden Algorithmen der Branche für die Abfrage-Verarbeitung.
Insgesamt stellen Googles bahnbrechende Suchtechnologien wie RankBrain, neuronales Matching, ScaNN und die TPU-Familie einige der wertvollsten technologischen Errungenschaften des letzten Jahrzehnts dar. Diese Technologien werden nun auch in Vertex AI Search genutzt, wodurch Entwickler Zugang zu semantischen Suchfunktionen in Google-Qualität erhalten – mit minimaler Latenz und zu vertretbaren Kosten.
Aber damit nicht genug…
Funktionen & Bedeutung für SEOs
Wenn wir unsere Inhalte und Webseiten für KI-basierte Suchmaschinen wie Perplexity, das neue bing und Googles SGE optimieren wollen, oder die Chance steigern wollen, dass Googles „AI Overviews“ Informationen von unserer Webseite zitiert, brauchen wir zunächst einmal irgendeinen Anhaltspunkt, ob wir in die richtige Richtung gehen. Wir müssen also die semantische Relevanz unserer Inhalte im Bezug auf Suchanfragen messen.
Vertex AI Search bietet uns hierfür quasi eine fertige hybride Suchmaschine an, die für jede Anfrage gleichzeitig sowohl eine Schlüsselwort- als auch eine semantische Suche auf Basis der Technologien durchführt, die Google auch in seiner eigenen Suche verwendet!
Kai Spriestersbach
Die Ergebnisse werden dann zusammengeführt und basierend auf ihren jeweiligen Bewertungen neu geordnet. Dadurch werden die Vorteile beider Suchansätze kombiniert und die Lücken, die jeder Ansatz für sich genommen lässt, geschlossen.
Ein weiterer wichtiger Aspekt ist das Verstehen und Umformulieren von Suchanfragen.
Nutzer tippen oft Suchanfragen falsch ein oder erinnern sich nicht genau an die richtigen Bezeichnungen. Hier kommen Techniken wie die Umformulierung und Erweiterung von Suchanfragen zum Einsatz.
Vertex AI Search bietet standardmäßig eine automatische, kontextbezogene Umformulierung und Erweiterung von Suchanfragen in den unterstützten Sprachen an.Dazu gehören neben der Wortstammbildung (Stemming) und Rechtschreibkorrektur auch das Hinzufügen verwandter Wörter und Synonyme sowie das Entfernen unwichtiger Wörter.
Diese Funktionen helfen der Suche dabei, die Intention hinter einer Suchanfrage besser zu verstehen und präzisere Ergebnisse zu liefern, selbst wenn die ursprüngliche Eingabe des Nutzers nicht optimal war, was insbesondere mit Blick auf die Suchmaschinenoptimierung eine wertvolle Informationsquelle darstellt.
Mit der Vertex AI Search bekommen wir nun ein Werkzeug direkt von Google an die Hand, mit dem wir ein besseres Verständnis der Nutzerintention hinter Suchanfragen erhalten, als auch überprüfen können, ob unsere Inhalte für Fragestellungen relevanter sind, als die unserer Mitbewerber!
Kai Spriestersbach
Bau Dir Dein eigenes Google!
Wir können nun also zu einem beliebigen Keyword einfach die Top 50 der rankenden Dokumente in einen eigenen Mini-Index direkt in der Google Cloud packen, um den ersten Teil von Googles zweistufigen Retrieval-Ansatz nachzubauen und können die selben Funktionen der API für die Extraktion und Erstellung von Inhalten verwenden, wie Google sie selbst in seiner Suche verwendet.
Nachdem wir also die Suche mit relevanten Dokumenten gefüttert haben, kann diese uns auch noch die wichtigsten Abschnitte herausfiltern, die dann als Grundlage für das KI-Sprachmodell dienen, um Antworten zu generieren oder Zusammenfassungen zu erstellen.
Das KI-SEO-Tool der Zukunft?
Umgehauen hat es mich, als ich gesehen habe, dass Googles Vertex AI Search gleich mehrere Möglichkeiten mitbringt, um besonders relevante Inhalte aus den gefundenen Dokumenten zu extrahieren.
Jedem SEO sollten diese Beispiele von Google das Wasser im Mund zusammen laufen lassen:
Jedes Suchergebnis kann folgende Inhaltstypen umfassen, die sich aus meiner Sicht perfekt für die Verwendung in SEO-Tools eignen:
1. Textauszug für die Snippet-Optimierung
Vertex AI Search erstellt automatisch einen kurzen Ausschnitt aus dem Dokument, der einen Überblick über den Inhalt gibt. Diese Auszüge werden ähnlich wie bei Google-Suchergebnissen unter jedem Treffer angezeigt und helfen Nutzern, die Relevanz einzuschätzen.
Hiermit erhalten SEOs quasi einen Einblick in den Mechanismus, der die automatisch generierten Snippets erstellt und können sehr viel gezielter für diesen optimieren!
2. Extrahierte Antwort für die Optimierung für „Featured Snippets“
Laut Googles eigener Dokumentation handelt es sich dabei um einen wörtlichen Textauszug aus dem Originaldokument, vergleichbar mit Google’s eigenen „Featured Snippets“. Diese Antworten stehen typischerweise am Anfang der Seite und bieten knappe, kontextbezogene Antworten auf Nutzeranfragen.
Hiermit lassen sich Texte also potentiell dahingehend optimieren, häufiger als Quelle für Googles Featured Snippets herangezogen zu werden!
3. Extrahierte Segmente für die Optimierung der „AI Summaries
In dieser Funktion liefert die Suche ausführlichere wörtliche Textauszüge aus einem Dokument, die mehr Kontext für KI-Sprachmodelle liefern als eine extrahierte Antwort. Diese Segmente können anschließend noch weiterverarbeitet werden, z.B. als Input für ein KI-Modell wie Gemini 1.5 um KI-generierte Zusammenfassungen zu erstellen, oder Vorschläge für die Verbesserung eines Dokumentes. Man könnte sogar den Inhalt direkt per KI verbessern, wenn man eine menschliche Qualitätssicherung nachschaltet.
Hiermit lassen sich wahrscheinlich nicht nur die „AI Summaries“ gezielt optimieren, sondern die Verbesserungen der Inhalte könnte auch zu einer Verbesserung des Rankings in der organischen Suche bei tragen und dabei sowohl die Nutzerzufriedenheit, als auch die Konversionsraten positiv beeinflussen.
Die Informationsextraktion lässt sich so konfigurieren, wie sie (mutmaßlich) auch in Googles Suche zum Einsatz kommt. So lässt sich beispielsweise die Anzahl der zu extrahierenden Textabschnitte pro Dokument festlegen, benachbarte Abschnitte für zusätzlichen Kontext einbeziehen und sogar die relevantesten Segmente auswählen oder weniger wichtige herausfiltern.
Kai Spriestersbach
Bonus: Dokumenten Handling like you are Google!!
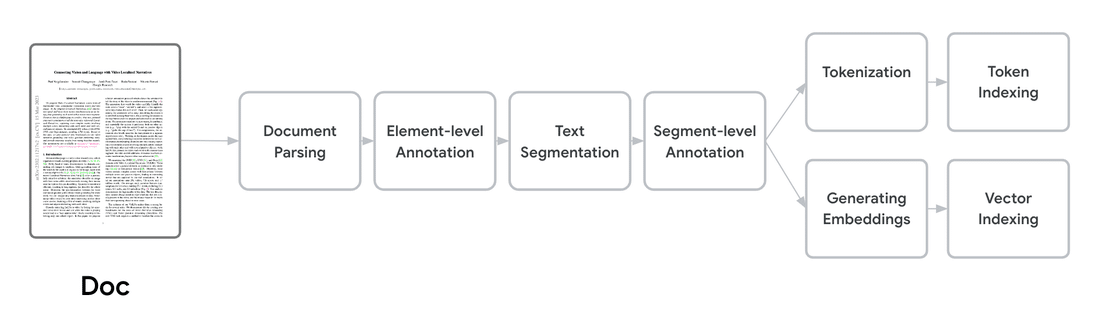
Wie jeder SEO weiß, ist es für eine Suchmaschine wichtig, die Struktur jedes Dokuments zu verstehen und sie angemessen zu verarbeiten, bevor die eigentliche Informationssuche und -bewertung stattfindet. Wer schon einmal selbst eine Suchmaschine oder ein RAG-System gebaut hat, weiß wie schwierig es sein kann, PDFs, HTML-Dateien und andere Dokumente so zu parsen und in Häppchen aufzuteilen, dass diese die Antworten der KI wirklich verbessert.
Vertex AI Search nimmt einem diese mühsame Arbeit komplett ab und geht dabei, wie Googles Suche, über die reine Textextraktion hinaus. Der Prä-Prozessor erkennt dabei sogar strukturelle und inhaltliche Elemente wie Überschriften, Abschnitte, Absätze und Tabellen, die die Organisation und Hierarchie verschiedener Dokumente definieren.
Diese Informationen werden genutzt, um die Dokumente intelligent in kleinere, abrufbare Segmente (Chunks) zu unterteilen. Dabei wird die Kohärenz semantischer Elemente bewahrt und Störfaktoren minimiert. Diese Methode ist effektiver als die weit verbreitete einfache Textsegmentierung, die oft die semantische Kohärenz nicht aufrechterhält.
Dieses Feature alleine hat mir nächtelang Kopfzerbrechen gemacht, als ich überlegt hatte, wie man eine KI-basierte Suche bauen würde.
Killer-Feature: Einblicke in den Knowledge Graph
Wir sind noch nicht am Ende. Denn sogar die Entitäts-Fetischisten kommen auf ihre Kosten! Google liefert, sozusagen als Sahne auf der Torte noch eine automatische Dokumenten- und Suchanfragen-Annotation mit Wissensgraphen mit.
Falls Du mit diesem Begriff nichts anfangen kannst: Ein Wissensgraph, auf englisch Knowledge Graph findet Informationen, indem die Beziehungen zwischen Entitäten in einem Graphen genutzt werden.
Google setzt Knowledge Graphen bereits seit 2012 in der Google-Suche ein und hat sogar 2013 für 30 Millionen das Unternehmen Wavii gekauft, um seinen Knowledge Graph zu verbessern. Dieser hilft Google dabei, Suchanfragen mehr Kontext zu geben, indem sie Informationen über Dinge, Personen oder Orte liefern, die Google bereits kennt.
Die Google-Suche nutzt Wissensgraphen, um auf ihr bestehendes Wissen und Verständnis des Webs zuzugreifen und Ergebnisse zu finden, die mit der Suchanfrage des Nutzers in Verbindung stehen, wie etwa Sehenswürdigkeiten, Prominente, Städte, geografische Merkmale, Filme und vieles mehr.
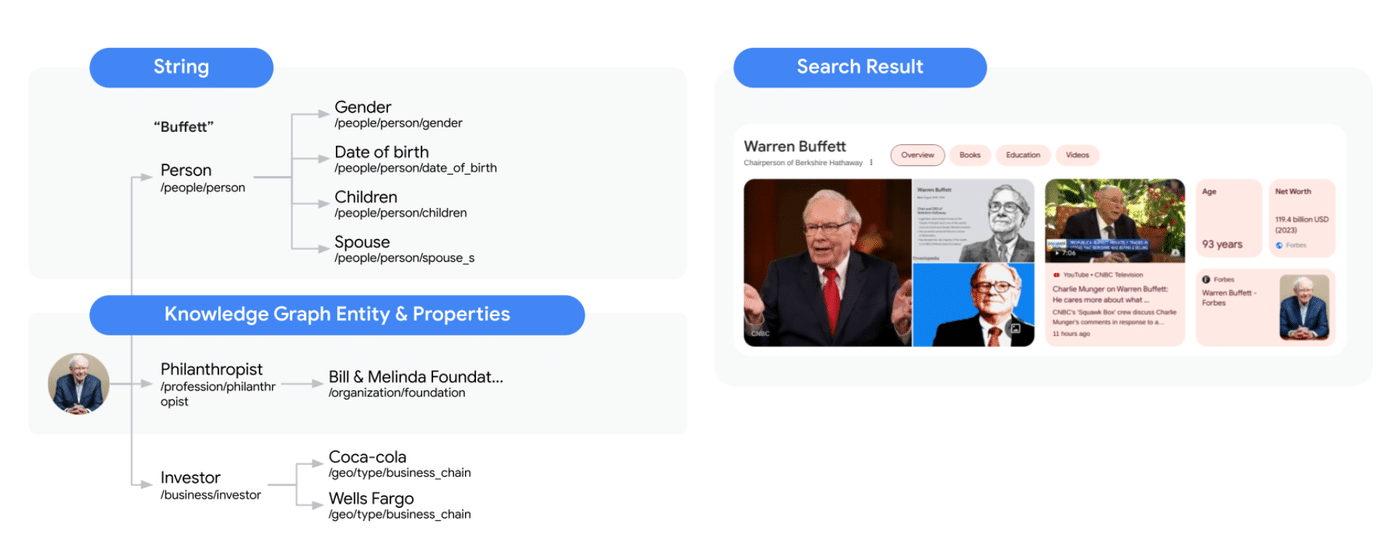
Wenn beispielsweise ein Dokument oder eine Suchanfrage das Stichwort „Buffett“ enthält, ist es sehr wahrscheinlich, dass sich dieses Keyword auf Warren Buffett bezieht.
Vertex AI Search annotiert Dokumente automatisch mit zusätzlichen Informationen über ihn aus dem Wissensgraphen der Google-Suche und fügt der ursprünglichen Anfrage verwandte Keywords. Dies erhöht die Wahrscheinlichkeit, dieses Dokument auch mit anderen Stichwörtern oder Themen zu finden, die mit ihm in Verbindung stehen.
Vertex AI Search identifiziert automatisch relevante Entitäten bei Anfragen sowie der Verarbeitung oder Zusammenfassung von Dokumenten mithilfe von Wissensgraphen und fügt diese den Annotationen hinzu, welche sich anschließend in strukturierte Daten überführen und der Seite zur semantischen Auszeichnung oder für die interne Verlinkung nutzen lassen.
Kai Spriestersbach
AI Content Advanced: Grounding via Google Search
Nach der Sahne auf der Torte, hier noch die Kirsche: Automatisiert generierte Texte bieten immer die Gefahr von Halluzinationen und Falschaussagen. Um die Korrektheit generierter Texte zu überprüfen lässt sich Googles Grounding API daher mit Google Search für alle Gemini-Modelle verwenden, um quellenbasiert Texte zu erstellen.
Dabei greift Googles Sprachmodell Gemini im Hintergrund auf die Google-Suche zu und erzeugt eine Ausgabe, die mit den relevanten Suchergebnissen „gegrounded“ ist, also deren Fakten und Aussagen auf den Informationen dieser Webseiten basieren.
Damit lassen sich Modelle mit aktuellem Wissen aus dem Internet verknüpfen, oder man nutzt eine Verankerung mittels eigener Daten.
Das beste ist: Hierbei lässt sich das Modell mit persönlichen Daten aus dem Vertex AI Search-Datenspeicher kombinieren. Damit kannst Du also Deine Unternehmensdaten, FAQ-Artikel, Blogbeiträge oder redaktionellen Inhalte quasi als Quellen für die generierung korrekter Antworten hinterlegen!
Diese Funktion befindet sich derzeit jedoch noch in der Vorschauphase.
Mein Fazit und Ausblick
Jetzt denkst du vielleicht, wow das ist eine ganze Menge. Und wenn du – wie ich – vorhast, diese Technologien für deine eigene SEO-Arbeit zu nutzen, hast du Recht.
Um derartig fortschrittliche Suchtechnologien zu implementieren, die eine mit der Google-Suche vergleichbare Suchqualität liefern, egal ob du sie GenAI verwendest oder nicht, bräuchtest du Jahre der Entwicklung und die Einstellung einer Vielzahl von Datenwissenschaftlern und Ingenieuren mit Spezialkenntnissen in ML, Suchmaschinen, DevOps und MLOps.
Oder einfach einen Account bei Googles Vertex AI Cloud.
Kai Spriestersbach
Ich bin, wie du vielleicht beim Lesen gemerkt hast, ziemlich gehyped, denn für SEOs eröffnet die Verfügbarkeit von Googles bislang geheimen Technologien wie RankBrain und dem Knowledge Graphen über Vertex AI vollkommen neue Möglichkeiten für Innovationen im Bereich der Suchmaschinenoptimierung.
Dazu liefert Google quasi die Technologie zur Verbesserung und Erstellung von Inhalte mit und bietet mit der Grounding API sogar endlich die Möglichkeit, die Korrektheit der generierten Aussagen zu verbessern.
Ich bin extrem gespannt, welche Toolanbieter zuerst von den neuen Möglichkeiten gebrauch machen werden. Meinen eigenen KI-SEO-Stack werde ich vollständig auf Vertex AI umstellen. Leider ist die Dokumentation aktuell noch ziemlich inkonsistent und weist große Lücken auf.
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.
Kai Spriestersbach ist erfolgreicher Unternehmer und digitaler Stratege mit einem Master-Abschluss in Web Science. Er ist Inhaber von AFAIK und verfügt über mehr als 20 Jahre Erfahrung im Aufbau und der Optimierung von webbasierten Geschäftsmodellen. Als einer der erfahrensten Search Marketing Experten im deutschsprachigen Raum hat er mehr als 25 Vorträge auf SEO- und Online-Marketing-Konferenzen in Deutschland und Österreich gehalten. In den letzten Jahren hat er sich intensiv mit Large Language Models beschäftigt und sich als Experte für die Textgenerierung mit Hilfe künstlicher Intelligenz etabliert. Seine Karriere begann er mit einer Ausbildung zum Mediengestalter (IHK), bevor er den Bachelor of Science (B.Sc) in E-Commerce absolvierte. Anschließend erwarb er den Master of Science (M.Sc) in Web Science und forschte an der RPTU im Bereich angewandter generativer KI.