Der Rummel rund um ChatGPT ist der größte Hype, den ich in den 40 Jahren miterleben durfte, die ich nun bereits auf dieser Erde bin. Dieser Chatbot erlaubte es zum ersten Mal jedem ganz einfach mit einer künstlichen Intelligenz zu sprechen. Das sorgte für eine wahre KI-Explosion. Nie zuvor in der Geschichte der Menschheit hat ein Produkt so schnell so viele Nutzer gewonnen. In den ersten zwei Monaten konnte der Chatbot von OpenAI bereits 100 Million registrierte Nutzer verzeichnen. Doch ich habe auch noch nie so viel Bullshit und unsinnige Aussagen zu einem Produkt gelesen, wie zu ChatGPT!

Schaut man sich bei Blogs, Twitter, LinkedIn oder eine der vielen Prompt-Communities um, auf denen Nutzerinnen und Nutzer die angeblich besten Tipps und Tricks rund um den Einsatz von ChatGPT teilen, fällt einem auf, wie verführerisch ein derartiger Hype auf uns Menschen wirken kann. Jeder will der oder die Erste sein und einen neuen Tipp zu ChatGPT teilen, den zuvor noch niemand gekannt hat. Dabei schalten so manche leider ihren Verstand aus und so verbreiten sich selbst die unsinnigsten Dinge wie ein Lauffeuer.
Bei der Recherche für mein aktuelles Sachbuch „Richtig Texten mit KI: ChatGPT, GPT-4, GPT-3 & Co.“ bin ich einer ganzen Reihe von populären Fehlannahmen und Missverständnissen begegnet, mit denen ich in diesem Artikel aufräumen möchte.
Damit du nicht auf diesen Bullshit hereinfällst, lass mich die größten Missverständnisse, rund um ChatGPT aufklären. Einige davon sind nur kleine Ungenauigkeiten, andere jedoch so grundlegend falsche Annahmen, dass sie die Arbeit mit der künstlichen Intelligenz sogar gefährlich machen können!
Ich will niemanden bloßstellen oder vorführen, daher nenne ich keine Quellen und habe Namen und Webseiten auf den Screenshots unkenntlich gemacht. Es geht nur darum zu zeigen, wie unreflektiert Informationen oder Prompts zu ChatGPT geteilt werden, die einfach keinen Sinn ergeben, wenn man einmal verstanden hat, wie GPT funktioniert.
1. Fehler: Falscher Umgang mit Bezeichnungen und Begriffen
Einer der häufigsten Fehler, der mir in den letzten Monaten begegnet ist, ist es, ChatGPT mit den großen Sprachmodellen dahinter zu verwechseln. Teilweise wird dann auch von ChatGPT-4 gesprochen, wie in diesem Beispiel, das es jedoch gar nicht gibt:

Fakt ist: ChatGPT ist der Chatbot von OpenAI, den man über die Webseite https://chat.openai.com/ erreichen kann. GPT-3, GPT-3.5 und GPT-4 hingegen bezeichnet die großen Sprachmodelle von OpenAI, die über Programmierschnittstellen, die sogenannten APIs genutzt werden können und unter anderem auch hinter ChatGPT stecken. Aber auch die meisten anderen kommerziellen KI-Text-Tools wie Jasper, Frase, Neuroflash und Co. setzen diese Schnittstellen ein, um ihren Produkten die Fähigkeiten künstlicher Intelligenz zu verleihen. Als zahlender Nutzer von ChatGPT PLUS lässt sich innerhalb von ChatGPT das Modell zwischen GPT-3.5 und dem neueren GPT-4 wählen, was wohl zu falschen Bezeichnungen wie ChatGPT-4 geführt hat.
Das mag auf den ersten Blick nur eine Ungenauigkeit sein, zeigt mir jedoch, dass der Autor oder die Autorin sich nicht eingehend mit der Technologie dahinter beschäftigt hat. Falls du also irgendwo so etwas liest, solltest du vorsichtig mit den Informationen und Tipps von dieser Person umgehen.
Und siehe da, der selbe Autor verwechselt nur eine Seite weiter den Begriff „Prompt“, der für die Anweisung an eine KI steht, mit der Antwort, also der Ausgabe der KI:

Doch damit noch nicht genug. Anstatt von Token bei der Längenbegrenzung zu sprechen, behauptet der Autor, GPT-4 wäre in der Lage bis zu 25.000 Wörter zu verarbeiten, im Gegensatz zu den angeblichen 8.000 von GPT-3.5:

Ich verstehe den Wunsch das Limit in Wörtern anzugeben, obwohl OpenAI diese lediglich in Form von Token angeben kann. Doch wieviele Wörter nun das in Token angegebene Limit ausmacht, lässt sich garnicht so einfach sagen. Denn der Begriff „Token“ bezieht sich auf eine Einheit von Text, die von der KI als separate Einheit verarbeitet wird. Ein Token kann ein Wort, eine Zahl, ein Satzzeichen, ein Symbol oder auch nur der Teil eines Wortes sein.
Eine Faustregel besagt, dass ein Token im Durchschnitt etwa ¾ eines Wortes in der englischen Sprache entspricht. In einem englischen Text wären 100 Token also etwa 75 Wörter. Deutsche Wörter enthalten im Durchschnitt jedoch mehr Token, so dass ein deutscher Text von 100 Token mitunter nur 50 Worte umfassen kann. Eine Aussage über das Limit von ChatGPT ist also nur in Tokens wirklich sinnvoll.
Das Beste ist jedoch, dass weder 8.000 Wörter, noch 8.000 Tokens das Limit von GPT-3.5 darstellt.
Auch hier hat der Autor zu schlampig recherchert, denn GPT-3.5 hat in Wahrheit ein Token-Limit von 4.097. GPT-4 eigentlich 8.192 und nur in einer besonderen Variante, nämlich dem größten und auch teuersten GPT-4-32K-Modell stolze 32.768 Token.
Okay, das ist nicht ganz einfach, aber kann man doch hinbekommen, oder?
Aber es geht noch weiter:
Ein weiteres schönes Beispiel für Bullshit findet sich im selben „ChatGPT Guide“ direkt im nächsten Absatz. Darin behauptet der Autor, GPT-4 wäre mittels gigantischer Mengen an Text trainiert worden und nennt als mögliche Größenordnung für die Textmenge „100 trillion parameters“:

Darin werden jedoch zwei unterschiedliche Dinge zusammengebraucht, die eigentlich nichts miteinander zu tun haben. Nämlich die Menge der Trainingsdaten, mit denen das Sprachmodell trainiert wurde und die Anzahl der Parameter, die innerhalb des Modells dafür sorgen, dass es seine Komplexität und „Intelligenz“ entwickeln kann.
Eine solche Aussage ergibt folglich überhaupt keinen Sinn!
Aber in dem Satz versteckt sich noch ein Fehler, der die populärste Falschinformation rund um das neue GPT-4 Sprachmodell darstellt: An vielen Stellen wird die Anzahl der Parameter von GPT-4 mit „100 trillion“ angegeben. Die amerikanische „trillion“ entspricht dabei unserer Billion, also 100 Billionen Parameter. Eine 1 mit 12 Nullen. Also 100.000 Milliarden oder ausgeschrieben 100.000.000.000.000 Parameter.
Vielleicht hast du schon einmal diese Grafik gesehen, die die Anzahl der Parameter von GPT-4 im Vergleich zu dessen Vorgänger GPT-3 anschaulich machen soll. Für ein paar Tage war das wahrscheinlich die am häufigsten geteilte Grafik bei LinkedIn:

Leider handelt es sich hierbei um kompletten Bullshit, wie ich im folgenden Artikel bereits dargelegt habe, denn die zunehmende Kommerzialisierung der Sprachmodelle und die zunehmende Konkurrenz durch Google, Meta, Aleph Alpha und Co. sorgt dafür, dass man bei OpenAI nicht mehr so detailliert über die neuesten Fortschritte spricht.
Die Wahrheit ist, dass OpenAI bis heute keinerlei nähere Informationen zu GPT-4s Aufbau veröffentlich hat. Es ist weder bekannt, inwieweit sich die Architekt im Vergleich zu dessen Vorgänger GPT-3 verändert hat, noch wie viele Parameter genau das Modell hat oder auf Basis welcher Trainingsdaten es trainiert wurde.
2. Fehler: Das Sprachmodell mit einem Wissensmodell verwechseln
Keine Frage: Es ist extrem unterhaltsam und verführerisch, ChatGPT nach Dingen zu fragen, die man selbst nicht weiß oder Texte schreiben zu lassen, die Aussagen enthalten, für die ein sehr breites Allgemeinwissen oder gar spezielles Expertenwissen notwendig ist. Zum Teil funktioniert das sogar, doch es ist nicht einfach zu erkennen, wann sich ChatGPT etwas „ausgedacht“ hat und wann eine Aussage häufig genug in den Trainingsdaten enthalten war, dass diese tatsächlich wahr ist und nicht nur zufällig entstanden ist. Insbesondere, wenn man sich selbst nicht gut in der Thematik auskennt ist es nahezu unmöglich, selbstbewusste Falschbehauptungen der KI zu erkennen.
Die Sprachmodelle hinter ChatGPT, beispielsweise GPT-3.5 und GPT-4 sind darauf ausgelegt, menschenähnliche Texte zu erzeugen. Sie tun dies, indem sie die Struktur und den Kontext von Sprache analysieren. Allerdings verstehen diese Modelle nicht die eigentlichen Inhalte der Texte und sind daher keine Wissensmodelle.
Diese Modelle können Fakten und Informationen weder erkennen noch speichern oder abrufen. In ihnen gibt es keine Datenbank oder strukturierte Speicherung von Informationen aus den Trainingsdaten. Sie speichern Texte nicht in ihrer ursprünglichen Form, sondern berechnen lediglich die Wahrscheinlichkeit einzelner Wörter oder Wortbestandteile basierend auf den vorausgegangenen Wörtern in den Trainingsdaten.
Trotz dieser Einschränkungen können Sprachmodelle tatsächlich erstaunliche Ergebnisse liefern, doch man sollte jede generierte Aussage zunächst einmal kritisch betrachten.
Das wird einem erst so richtig klar, wenn man sich einmal die Wahrscheinlichkeiten der einzelnen Wörter bzw. Tokens anschaut:
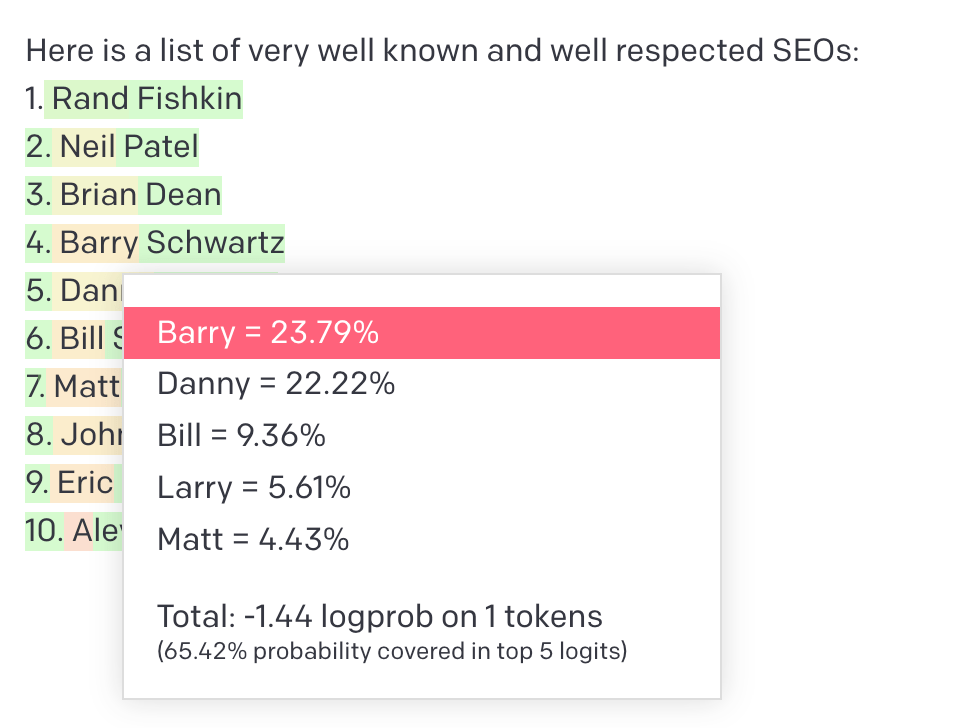
In diesem Beispiel habe ich GPT-3 eine Liste der bekanntesten und angesehensten SEOs erzeugen lassen. Wie ein Klick auf „Barry“ verrät, war die Wahrscheinlichkeit dass statt Barry Schwarz ein gewisser „Danny“ auf Platz 4 liegt extrem knapp, gefolgt von „Bill“, „Larry“ und „Matt“. Im Kontext SEO folgt auf Barry dann „Schwartz“ und auf Danny dann „Sullivan“ und so entsteht (in diesem Fall) eine Liste tatsächlich existierender Personen.
Wie du hoffentlich beim Lesen dieses Artikels festgestellt hat, ist ChatGPT alles andere als perfekt. Aufgrund des einfachen Funktionsprinzips kann es selbst bei Zusammenfassungen vorhandener Texte passieren, dass ChatGPT Informationen falsch wiedergibt. Außerdem ist ChatGPT nicht auf dem neuesten Stand des Wissens: Da ChatGPT auf Texten trainiert wurde, die zu einem bestimmten Zeitpunkt verfügbar waren, ist es nicht immer auf dem neuesten Stand des Wissens. Es ist wichtig, die generierten Inhalte auf Aktualität und Richtigkeit zu überprüfen.
Wenn du ChatGPT beispielsweise anweist, als Akademiker/in zu agieren und zu einem Thema deiner Wahl zu recherchieren und die Ergebnisse in Form eines Aufsatzes oder Artikels zu präsentieren, kannst du die KI zwar anweisen, zuverlässige Quellen zu finden, das Material gut zu strukturieren und mit Zitaten zu belegen, doch das heißt noch lange nicht, dass es nur korrekte Informationen ausgeben wird.
Ich persönlich rate von einem solchen Vorgang generell ab, denn um zu erkennen, was davon richtig und was falsch ist, ist eine wahre Syssyphusaufgabe. Wenn man nicht gerade Experte in diesem Thema ist, muss man jede einzelne Aussage überprüfen, was am Ende sogar aufwändiger ist, als zuerst eine Recherche von Fakten und Quellen durchzuführen und ChatGPT nur noch dafür zu verwenden, diese zusammenzufassen.
Man kann sich erst ein Paper mit Hypothesen von der KI schreiben lassen und anschließend versuchen, Belege und Quellen für dessen Behauptungen zu finden, das ist jedoch gerade nicht, wie Wissenschaft funktioniert. Echte Wissenschaft sichtet erst alle Quellen und Fakten und zieht danach daraus ihre Schlüsse. Nicht umgekehrt!
Übrigens ist GPT-4, im Vergleich zu GPT-3.5 erstaunlich gut darin geworden, geeignete Quellen zu recherchieren, wie das folgende Beispiel anschaulich demonstriert:
GPT-3.5
Während die meisten Quellen, die GPT-3.5 liefert garnicht existieren:

GPT-4
Sind die meisten Quellen von GPT-4 korrekt und sogar die DOI-Nummern stimmen zum Teil:

Außerdem versteht GPT-4 den Inhalt der Behauptung im Titel der angeblichen Dissertation und liefert zumindest den wichtigen Hinweis, dass andere Rankingfaktoren ebenfalls eine Rolle spielen, auch wenn es diese nicht alle korrekt benennt.
Sei also bitte extrem vorsichtig, wenn du Aussagen, Daten und Informationen der KI veröffentlichst, oder dir diese sogar zu eigen machst. Führe stets einen Fact-Check durch!
3. Fehler: ChatGPT kann nicht auf das Internet zugreifen
Egal ob ChatGPT eine Zusammenfassung schreiben soll, oder man es einen Artikel schreiben lässt, der besser sein soll als ein vorhandener Text aus dem Internet. Es ist kompletter Unsinn eine URL in einem Prompt zu verwenden, da ChatGPT (derzeit zumindest) weder in der Lage dazu ist, den Inhalt auf dieser Seite live abzurufen, noch auf Basis einer URL den exakten Text aus den Trainingsdaten hervorzukramen.

ChatGPT wird die Wörter in der URL, genau wie jedes andere Wort in der Anweisung verwenden, um eine möglichst wahrscheinliche Antwort zu generieren, die so aussieht, als hätte es tatsächlich die Webseite abgerufen!
Noch dümmer ist es zu glauben, man könnte ChatGPT mit einem „Outrank Article-Prompt“ dazu bringen einfach einen besseren Artikel als den des Wettbewerbers zu schreiben. Doch das findet sich nicht nur in zahlreichen ChatGPT Guides und Prompt-Communities, sondern wird auch von dem einen oder anderen SEO da draussen munter geteilt, ohne Ahnung davon zu haben, was dabei wirklich geschieht.

Übrigens arbeitet OpenAI gerade an Plugins, die genau das lösen und testet sogar einem neuen Modell, dass auf das Internet zugreifen kann. Doch das sogenannte „Browsing“-Modell befindet sich derzeit noch in der Alpha-Phase und steht nur sehr wenigen, ausgewählten Testnutzern zur Verfügung.
Ein Beispiel für die Möglichkeiten, die sich durch das Browsen für ChatGPT-Nutzer ergeben, ist die Fähigkeit, aktuelle Informationen zu finden und darauf zuzugreifen. So kann ChatGPT beispielsweise neueste Informationen über die aktuelle Oscarverleihung abrufen und gleichzeitig seine Fähigkeiten im Dichten von Gedichten einsetzen. Dies zeigt, wie das Browsen das Nutzungserlebnis von ChatGPT erweitern kann. Das Plugin ermöglicht es den Sprachmodellen in ChatGPT, Informationen aus dem Internet zu lesen und erweitert damit die Menge an Inhalten, über die diese sinnvoll sprechen bzw. schreiben können.
4. Fehler: Die Selbstauskunftsfähigkeiten von ChatGPT überschätzen
Da sich das „Wissen“ von ChatGPT ausschließlich durch die statistische Analyse großer Textmengen ergibt, kann es nur sehr schlecht konkrete Fragen zu Details über sich selbst beantworten. ChatGPT kann beispielsweise nicht wissen, wieviel Prozent der Trainingsdaten in einer bestimmten Sprache vorlagen oder welche Webseiten oder Autoren in den Trainingsdaten wie häufig enthalten waren.
Ein paar grundlegende Informationen zu seinen eigenen Eigenschaften bekommt ChatGPT zwar von den Entwicklern über die sogenannten System-Prompts mitgeteilt, beispielsweise dass es „ChatGPT“ heißt, ein Chatbot ist und möglichst neutral und sachlich antworten soll, doch bei anderen Fragen nach spezifischen Details, reimt sich das Sprachmodell hinter ChatGPT schlicht und einfach etwas auf Basis der Wort-Wahrscheinlichkeiten zusammen.
Im folgenden Beispiel behauptet ChatGPT beispielsweise es wäre einzig und allein auf Basis englischer Texte trainiert worden, um im selben Chatverlauf einzuräumen, dass es möglich sei, dass auch deutschsprachige Texte in den Trainingsdaten enthalten sein könnten:
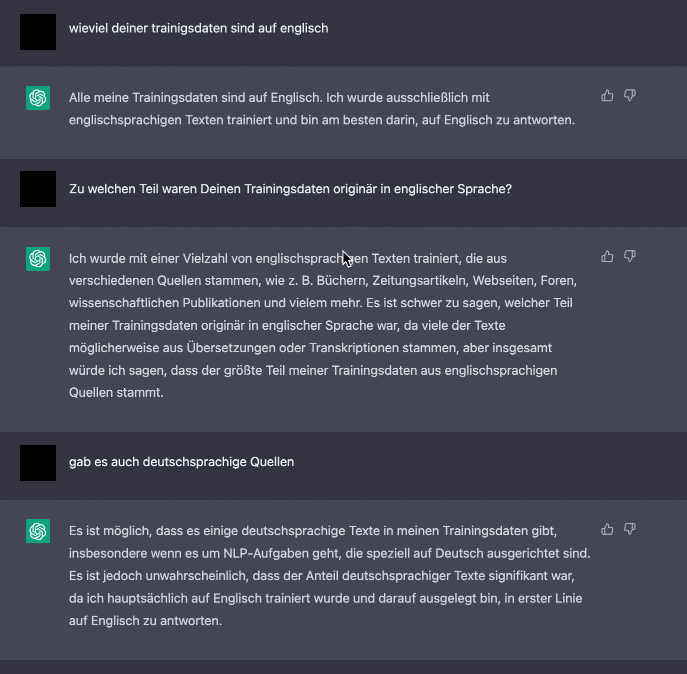
Verwende ChatGPT nicht dazu, etwas über ChatGPT zu erfahren. Die Informationen, die zur Beantwortung dieser Fragen notwendig wären, konnten im September 2021 noch gar nicht in den Trainingsdaten enthalten sein!
5. Fehler: Zu lange Texte oder Themen vermischen
Wenn man sich ein wenig auf YouTube zum Thema ChatGPT umschaut, stolpert man schnell über Videos, in denen jemand behauptet einen absurden Betrag damit verdient zu haben, ChatGPT ein Buch schreiben zu lassen und dieses anschließend bei Amazon über das Kindle Direct Publishing Programm verkauft zu haben. Wer sich ein bisschen länger mit ChatGPT beschäftigt hat, weiß, dass es sich dabei nur um Lockangebote und Heilsversprechend irgendwelcher Abzock-Unternehmer handeln kann, denn ChatGPT ist technisch gesehen gar nicht dazu in der Lage, ein ganzes Buch zu schreiben.
Doch auch viele angebliche ChatGPT-Experten behaupten, es sei möglich, ein vollständiges Buch mit nur einem Klick schreiben zu lassen.

Durch die Beschränkung der maximalen Ausgabe des Sprachmodells ist sowohl die Länger der Anweisung an ChatGPT, als auch die maximale Länge der Antwort der KI begrenzt. Je nach verwendetem Modell kann ChatGPT derzeit maximal 1.700 Worte auf einmal ausgeben.
Lustigerweise findet man auf Prompt-Seite wie AIPRM zu solchen Bullshit-Prompts kaum kritische Kommentare. Offenbar schaut sich niemand mehr als das den Anfang des generierten Buches an:

Natürlich kann man die KI nun dazu bringen, die Ausgabe immer wieder fortzusetzen und die erzeugten Teile anschließend in ein Dokument kopieren. Allerdings wird die Geschichte in diesem Fall weder einen roten Faden haben noch in sich selbst konsistent sein.
Aufgrund der beschränkten Eingabe kann ChatGPT beispielsweise den Anfang des Buches gar nicht mehr sehen, obwohl es diesen selbst geschrieben hat! So passiert es schnell, dass Rollen ihre Namen ändern, die Handlung absurd hin und her springt, sich Handlungen wiederholen oder das Ganze eben wirkt, wie eine zufällige Aneinanderreihung irgendwelcher Kapitel aus beliebigen fremden Büchern.
Es ist eine wahre Kunst, die KI bei jeder Anfrage erneut den Gesamtzusammenhang der Geschichte klarzumachen und ihr genau zu sagen, an welcher Stelle der Geschichte sie sich gerade befindet, damit die einzelnen Kapitel detailliert und spannend erzählt werden, aber gleichzeitig nicht der Blick für das große Ganze verloren geht.
Ebenso wie bei seiner Ausgabe ist ChatGPT auch bei der Eingabe begrenzt. Bei einem überlangen Text, den die KI umschreiben, zusammenfassen oder übersetzen soll, erhält man zwar eine Fehlermeldung in ChatGPT, doch selbst ernannte „Prompt Engineers“ sind längst auf die Idee gekommen, einen längeren Text in mehrere Stücke zu teilen und diese nach und nach der KI zu „fressen“ zu geben. Nach der Stück für Stück Eingabe weisen diese Möchtegern-Gurus ChatGPT dann an, den gesamten Text zu verarbeiten.
Das führt allerdings zwangsläufig dazu, dass sich die KI etwas ausdenkt, denn mit diesem angeblichen „Trick“ lässt sich die Beschränkung der Ein- und Ausgabe des Sprachmodells nicht aushebeln!
Der Einzige Weg, längere Texte in ChatGPT zu verarbeiten besteht darin, den Text Stück für Stück in das Chatfenster zu kopieren und dabei jedes Mal die Anweisung, was damit geschehen soll zu wiederholen. Das Gesamtergebnis muss man dann allerdings aus den Teilergebnissen wieder zusammensetzen. Eine Analyse über den gesamten Inhalt auf einmal, beispielsweise „die Kernaussage zu finden“ ist dabei leider nicht möglich.
ChatGPT berücksichtigt also ungefähr die letzten 1.500 bis 1.700 Wörter in einem Chatverlauf. Dabei spielt es übrigens keine Rolle, ob das eine Anweisung von Dir oder eine Ausgabe vom Chatbot ist. Nur dadurch ist es überhaupt möglich Rückfragen zu stellen, Dinge noch einmal neu formulieren zu lassen oder Aufgaben fortzusetzen. Doch das heißt im Umkehrschluss auch, dass ChatGPT bei jeder weiteren Frage auch die Antwort davor und je nach Länge auch vorherige Fragen und Antworten „sieht“, wenn du eine neue Aufgabe stellst.
Diskutierst du beispielsweise zunächst über Ethik mit der KI und willst dann plötzlich wissen, welche Farbe Äpfel haben, wird die Antwort womöglich deutlich philosophischer ausfallen, als wenn du ChatGPT in einem neuen Chatverkauf nach der Farbe von Äpfeln fragst.
Du solltest idealerweise für jede neue Aufgabe, auf jeden Fall aber für jedes neue Thema, zunächst einen neuen Chat in ChatGPT starten. Damit stellst du sicher, dass dir vorhergegangene Informationen und Anweisungen nicht dabei in die Quere kommen, die neue Aufgabe zu lösen.
6. Glauben ChatGPT versteht alles und kann alles
Für jeden der glaubt, das Thema KI sei nur ein Sturm im Wasserglas und ebenso schnell vorbei wie der Crypto-Scam oder der Metaverse-Bullshit findet sich jemand, der der aktuellen KI bereits alles zutraut.
So finden sich auf Prompt-Sharing-Seiten zum Teil absurde Anweisungen an die KI, die ihr Aufgaben stellen, die sie schlicht und einfach gar nicht lösen kann. Doch anstatt zu sagen, dass es der Aufgabe gar nicht gewachsen ist, wird ChatGPT, ähnlich der Bitte eine Webseite auf Basis einer URL zusammenzufassen, sich auf Basis der bekannten Informationen etwas zusammenfantasieren, was dann zum Teil so aussieht, als hätte es tatsächlich die gewünschte Aufgabe ausgeführt.
Beispielsweise verwendet ein beliebter Prompt bei datafit, der sogenannte „Human-like Rewriter – V1.6“ unter anderem die Anweisung „Enabled Plagiarism: Disabled Anti-Plagiarism: Enabled Uniqueness: 100%“, obwohl ChatGPT weder in der Lage ist zu verstehen, ob ein erzeugter Text möglicherweise ein Plagiat ist, noch dies mittels einfacher Anweisung zu verhindern.

Ebenso wenig ist ChatGPT in der Lage zu verstehen, was die Anweisung „Please format the generated blog article in a professional format and not an AI format.“ meint, die Anweisung „Utilize uncommon terminology to enhance the originality of the piece“ hingegen kann das Sprachmodell tatsächlich verstehen und umsetzen.
Ich habe tatsächlich schon Prompts wie „Outrank the competition with an in-depth, SEO-optimized article based on [URL]. Be like your competition, just a little better ;-)” gesehen, die abgefeiert wurden, als wären sie der heilige Gral der SEO-Intelligenz.
Ebenso unsinnig ist es, ChatGPT nach spezifischen Informationen zu fragen, wie zum Beispiel einer Liste von Suchbegriffen samt Suchvolumen und der SEO-Wettbewerbsdichte oder eine Liste der größten Städte eines Landes mit der Anzahl der Einwohner. Hier wird ChatGPT die wahrscheinlichste Antwort generieren, die jedoch noch lange nicht korrekt sein muss!

ChatGPT wurde eben darauf trainiert Texte zu generieren, die uns Menschen gefallen. Daher merken die Benutzer derartige Prompts häufig gar nicht, dass ihre Anweisung oder zumindest Teile davon im Grunde keinen Sinn machen. Bitte verwende keine Prompts unreflektiert. Es unzählige dumme Prompts in den Prompt-Engineering-Communities, Browser-Plugins oder Sammlungen der vermeintlich besten Prompts da draußen.
Für derartige Aufgaben könnte in Zukunft jedoch das neue „Code interpreter“ Modell eingesetzt werden, das sich derzeit noch in der Alpha-Phase befindet und nur einer sehr kleinen Anzahl an Benutzern in ChatGPT zur Verfügung steht. Damit kann ChatGPT in einer geschützten Umgebung mit einem Python-Interpreter arbeiten. Während einer Chat-Unterhaltung bleibt die Sitzung aktiv und verschiedene Code-Aufrufe können sogar aufeinander aufbauen. Es ist außerdem möglich, Dateien hochzuladen und Ergebnisse herunterzuladen.
Der erzeugte und ausgeführte Python Code wird dabei auch angezeigt, kann also jederzeit angepasst und wo anders oder in ChatGPT wieder ausgeführt werden. Es geht jedoch nicht darum, ChatGPT in eine Entwicklungsumgebung zu verwandeln, sondern kurze Code-Snippets zur Lösung konkreter Aufgaben zu erzeugen und einzusetzen, die das Sprachmodell alleine nicht durchführen kann (beispielsweise Rechenoperationen oder die Erzeugung von Plots, Diagrammen oder Bildern).
Das Besondere ist, dass das experimentielle Modell selbstständig erkennen soll, wenn es Python Code benötigt, um eine Aufgabe zu erledigen, dann diesen selbst schreibt und und direkt ausführt!
Dies ermöglicht beispielsweise die Analyse und Visualisierung von Daten bis zu 100 MB, wie zum Beispiel Tabellen mit Finanzdaten. Besonders für Personen ohne Data Science und Python-Kenntnisse eröffnet dies neue Möglichkeiten.
Zusammenfassung und Fazit
Nachdem wir in diesem Artikel die größten Fehler im Umgang mit ChatGPT betrachtet haben, sollte die Nutzung dieser faszinierenden KI-Technologie für dein Schreiben nun leichter und effektiver werden. Doch die Reise in die Welt der generativen Künstlichen Intelligenz hat gerade erst begonnen – es gibt noch so viel mehr zu entdecken und zu lernen.
ChatGPT ist nur ein Werkzeug und damit nur so effektiv wie die Person, die es benutzt. Man könnte sogar sagen, dass die KI nur maximal so schlau ist, wie die Person die sie bedient. Die Erstellung von effektiven ChatGPT-Aufforderungen erfordert sorgfältige Überlegungen und viel Liebe zum Detail. Es passiert schnell, dass man Fehler zu begeht, die die Effektivität deiner Prompts und die Gesamtqualität der Ergebnisse massiv beeinträchtigen können.
Generell ist es wichtig, ChatGPT genügend Informationen zu geben, um den Kontext und den Zweck des Gesprächs zu verstehen. Achte darauf, dass deine Aufforderungen kurz und bündig sind, und vermeide unnötige Details oder Anweisungen. Während offene Fragen nützlich sein können, um detailliertere Antworten zu erhalten, können zu vage oder offene Aufforderungen verwirrend und für das ChatGPT schwer zu verstehen sein. Achte darauf, dass du genügend Kontext und Hinweise gibst, um das Gespräch sinnvoll zu lenken.
Damit so etwas nicht passiert: Hol‘ Dir mein Buch
Hol dir jetzt das fundierte Sachbuch zum Schreiben mit KI, das dir hilft die Funktionsweise der KI zu verstehen und dabei sogar auf das aktuellste Sprachmodell in ChatGPT nämlich GPT-4 eingeht. Als ChatGPT vorgestellt wurde, arbeitete ich bereits seit mehr als einem Jahr mit KI-Text Tools auf Basis von GPT-3, dem Vorgänger des großen Sprachmodells GPT-3.5 hinter ChatGPT. Mittlerweile ist dessen Nachfolger GPT-4 veröffentlicht wurden und ich habe mein Wissen und die gemachten Erfahrungen in mein Buch „Richtig Texten mit KI: ChatGPT, GPT-4, GPT-3 & Co.“ gepackt, das am 23. Mai im mvg Verlag erscheint.

Darin erfährst du alles, was du über KI-gestütztes Schreiben wissen musst, und wie du ChatGPT und andere KI-Text-Tools optimal einsetzen kannst. Egal, ob du Blog-Posts, Artikel, Slogans, Werbetexte oder sogar wissenschaftliche Arbeiten und kreative Texte verfassen möchtest, hier findest du die Anleitung und das notwenige Hintergrundwissen dazu.
Das Buch erscheint am 23.5 im mvg Verlag und
kann ab sofort bei Amazon vorbestellt werden!
Keine Angst, dass das Buch längst veraltet ist, wenn es erscheint: Der mvg Verlag hat seine Prozesse gestrafft, so dass ich bis Mitte April das Manuskript erweitern und aktuell halten konnte und das Buch aktuell gedruckt und Anfang Mai an dich ausgeliefert wird. Außerdem bekommst Du als Buchkäuferin oder Buchkäufer neben meiner Liste der besten und effektivsten Prompts auch laufend Aktualisierungen und Erweiterungen.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




