Alle Käuferinnen und Käufer erhalten laufenden Erweiterungen und Aktualisierungen, die sich aufgrund neuer Entwicklungen bei ChatGPT, GPT-4 & Co. ergeben.
Möchtest du automatisch weitere Updates, News und Tipps von mir, zum Thema „ChatGPT, GPT-4 und Co.“ per E-Mail erhalten? Dann melde Dich jetzt für meinen Newsletter an:
Melde Dich jetzt an und bekomme News und Updates von mir:
Registriere dich jetzt für meinen Newsletter und erhalte alle Informationen zum Buch sowie aktuellste Informationen rund um die Themen KI, SEO und erfolgreiche Webseiten direkt in dein E-Mail-Postfach!
Keine Sorge, ich mag selbst keinen Spam und Deine Daten sind bei mir in guten Händen. Gib einfach deine E-Mail-Adresse ein und klicke auf den Registrierungs-Button. Anschließend bekommst du eine E-Mail, in der du deine Anmeldung bestätigst: Das dauert nur wenige Sekunden!
Update 1: ChatGPT bekommt mehr Datenschutz!
In meinem Buch habe ich noch geschrieben, dass es keine Möglichkeit gibt, der Verwendung der übermittelten Daten zu widersprechen. Nach der Sperrung von ChatGPT in Italien hat sich hier endlich etwas getan:
- Es gibt nun eine Möglichkeit des Opt-Outs. Leider bislang nur über ein Google-Formular, was in Sachen Datenschutz aus meiner Sicht keine gute Lösung ist.
Detaillierte Informationen darüber, welche Daten OpenAI wie genau verwendet, findet man außerdem in einem neu geschaffenen FAQ-Eintrag. - OpenAI hat die Möglichkeit eingeführt, den Chatverlauf in ChatGPT auszuschalten. Gespräche, die ohne Chatverlauf geführt werden, werden somit nicht mehr zum Trainieren und Verbessern der Modelle verwendet und erscheinen nicht in der Verlaufssidebar.
Diese Einstellungen, die ab heute für alle Benutzer verfügbar sind, befinden sich in den ChatGPT-Einstellungen und können jederzeit geändert werden. Wenn der Chatverlauf deaktiviert ist, werden neue Gespräche nur noch für 30 Tage gespeichert, um diese bei Bedarf auf Missbrauch zu überprüfen, bevor sie endgültig gelöscht werden. - Außerdem arbeitet OpenAI an einem neuen ChatGPT Business-Abonnement. Dies ist gedacht für Personen, die mehr Kontrolle über ihre Daten benötigen, sowie für Unternehmen, die ihre Endbenutzer verwalten möchten. ChatGPT Business wird den API-Datennutzungsrichtlinien folgen, was bedeutet, dass die Daten der Endbenutzer standardmäßig nicht zum Trainieren unserer Modelle verwendet werden. ChatGPT Business wird in den kommenden Monaten verfügbar sein.
- Schließlich erleichtert eine neue Exportoption in den Einstellungen den Export der eigenen ChatGPT-Daten und das Verständnis der von ChatGPT gespeicherten Informationen. Man erhält hierüber eine Datei mit den Gesprächen und allen anderen relevanten Daten per E-Mail.
Update 2: ChatGPT bekommt Zugriff auf das Internet
Im Buch habe ich an vielen Stellen darauf hingewiesen, dass ChatGPT keinen Zugriff auf das Internet hat und auch keine aktuellen Informationen (alles nach September 2021) in die Trainingsdaten einfließen können. Das ist für die Modelle GPT-3.5 und GPT-4 auch korrekt. Laut OpenAI haben frühere Arbeiten wie WebGPT, GopherCite, BlenderBot2, LaMDA2 und andere bereits gezeigt, dass Sprachmodelle, die Informationen aus dem Internet verwenden können, über ihren Trainingskorpus hinausgehen und aktuelle Daten nutzen können.
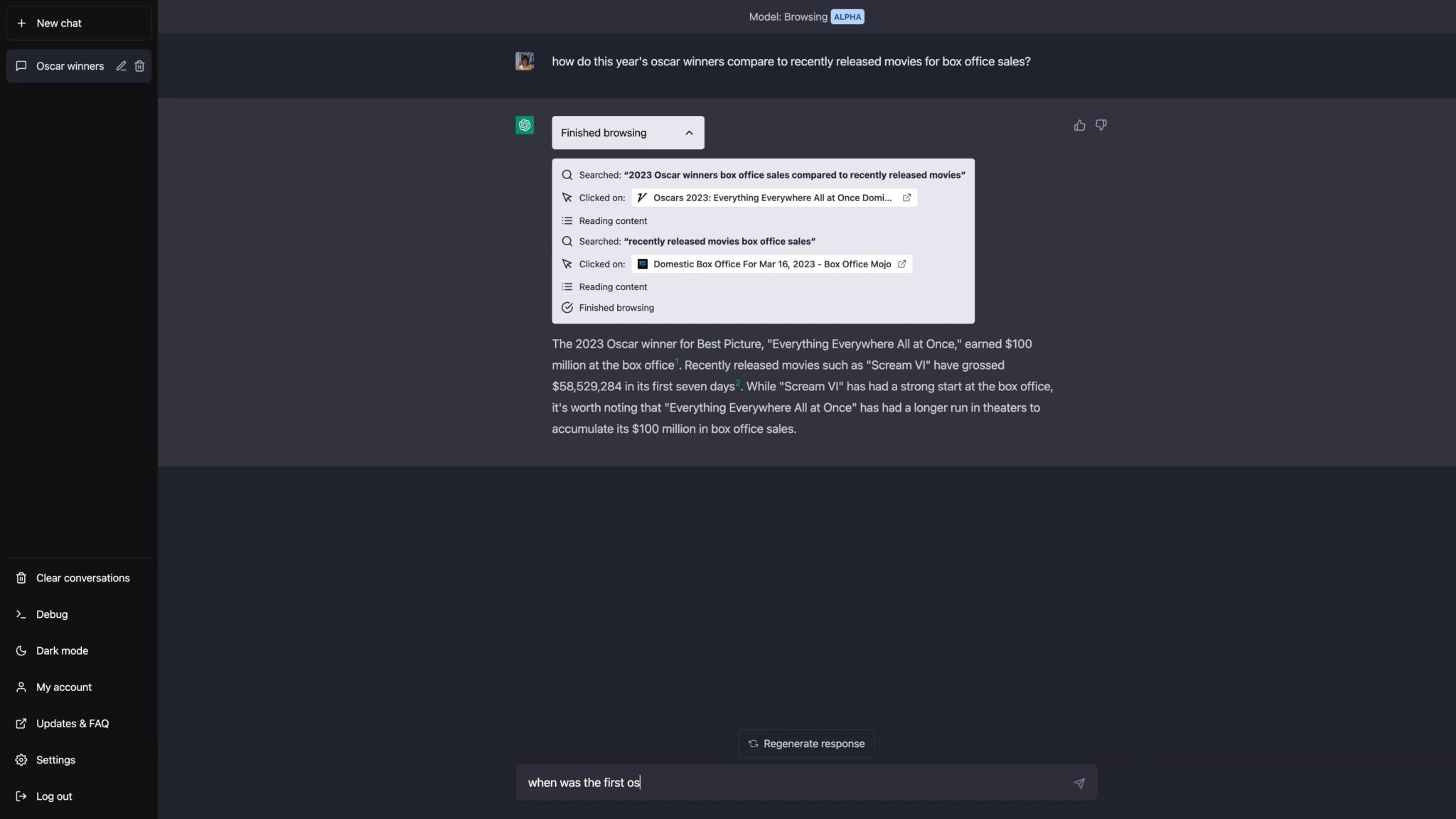
Für ChatGPT gibt es jedoch ein neues Model, das das Durchsuchen des Internets ermöglicht. Dieses Feature wurde von vielen Nutzern gewünscht, da das aktuelle Modell nur Daten bis 2021 enthält. Das Plugin ist aktuell noch als Alpha-Version gekennzeichnet, was bedeutet, dass es noch Fehler enthalten kann und nur sehr wenigen Nutzern zur Verfügung steht. Einige Nutzer haben ihre Erfahrungen mit dem Plugin bereits auf Reddit geteilt. Dabei wurden sowohl Probleme als auch Lösungsansätze diskutiert, wie zum Beispiel das Festlegen einer Zeitgrenze für das Durchsuchen des Internets, um endlose Suchschleifen zu vermeiden. Ein Nutzer schrieb: “Wenn ich meiner Aufforderung ’nicht länger als zehn Minuten suchen und mich fragen, wenn mehr Zeit benötigt wird‘ hinzufüge, antwortet es jedes Mal schnell. Wenn ich das nicht in meiner Aufforderung einschließe, sagt es manchmal einfach ‚Suche‘ für immer.“ Es wurde auch festgestellt, dass das Plugin möglicherweise nur zuverlässige, von OpenAI ausgewählte Quellen durchsucht.
Ein Beispiel für die Möglichkeiten, die sich durch das Browsen für ChatGPT-Nutzer ergeben, ist die Fähigkeit, aktuelle Informationen zu finden und darauf zuzugreifen. So kann ChatGPT beispielsweise neueste Informationen über die aktuelle Oscarverleihung abrufen und gleichzeitig seine Fähigkeiten im Dichten von Gedichten einsetzen. Dies zeigt, wie das Browsen das Nutzungserlebnis von ChatGPT erweitern kann. Das Plugin ermöglicht es den Sprachmodellen in ChatGPT, Informationen aus dem Internet zu lesen und erweitert damit die Menge an Inhalten, über die diese sinnvoll sprechen bzw. schreiben können.
Ein kurzes Beispiel-Video, wie das Ganze aussehen wird, findest Du im Blog bei OpenAI.
OpenAI hat mittlerweile angekündigt, dass alle Abonnenten von ChatGPT Plus zwei neue Funktionen als Beta erhalten: So wird man das Web-Browsing Modell und Plugins für alle Kunden aktivieren!
Um darauf zuzugreifen, müsst ihr nicht nur ChatGPT Plus abonniert haben, sondern die beiden Funktionen auch erst einmal im neuen Beta-Panel aktivieren. Plugins müssen zudem erst einzeln installiert werden. Dafür geht ihr erst einmal auf die Website https://chat.openai.com/. Dort wählt ihr im Model-Switcher die Option „Plugins“. Im Dropdown-Menü wählt ihr den „Plugin Store“ und könnt dort Plugins installieren bzw. aktivieren.
Anleitung: So sperrst Du Deine Website für ChatGPT
Zum Glück lässt sich das neue Browsing-Plugin von ChatGPT aussperren und damit verhindern, dass Nutzer Texte der eigenen Webseite mittels Sprachmodell auswertet, übersetzt, umschreibt oder anderweitig nutzt. Das Plugin verwendet die Bing-Such-API, um Inhalte aus dem Web abzurufen. Um die Urheberrechte von Inhalten zu respektieren und die Normen des Internets einzuhalten, verwendet das Browser-Plugin den User-Agent-Token „ChatGPT-User“ und hält sich an die robots.txt-Anweisungen. Dieser User-Agent wird nur für direkte Aktionen im Auftrag von ChatGPT-Nutzern verwendet und nicht für automatisches Crawling.
Somit lässt sich ChatGPT mit der folgenden Anweisung in der robots.txt Datei explizit aussperren:
# Block ChatGPT-Users from accessing via browsing plugin
User-agent: ChatGPT-User
Disallow: /Falls Du Deine vorhandene robots.txt erweitern willst, beachte bitte, dass nach jedem Block von Allow oder Disallow-Anweisungen immer eine Leerzeile folgen muss, bevor ein neuer User-agent adressiert werden kann!
Update 3: ChatGPT wird zum Data Scientist
Stell Dir vor, du könntest die Finanzdaten der letzten 50 Jahre und eine Liste der wichtigsten Erungenschaften eines Unternehmens in die KI stecken und bekommst in wenigen Sekunden einen hervorragenden Artikel mit spannenden Analysen und Insights geschrieben, der auf die Auswirkungen von neuen Produkten, dem Abgang oder Wechsel von Spitzenpersonal oder Veränderungen des Marktes eingeht und sich dabei an die zur Verfügung gestellten Zahlen, Daten und Fakten hält. Zusätzlich bekommst du nicht nur den Text geliefert, sondern auch entsprechende Visualisierungen von der KI erstellt, die du zur Verdeutlichung im Artikel nutzen kannst und damit noch viel schneller Insights aus Daten generieren kannst!
Genau das wird bald möglich sein, denn ChatGPT entwickelt sich weiter und bietet nun einen „Code Interpreter“ an, der Python-Code erstellen und ausführen kann. ChatGPT kann damit in einer geschützten Umgebung mit einem Python-Interpreter arbeiten. Während einer Chat-Unterhaltung bleibt die Sitzung aktiv und verschiedene Code-Aufrufe können sogar aufeinander aufbauen. Es ist außerdem möglich, Dateien hochzuladen und Ergebnisse herunterzuladen.
Der erzeugte und ausgeführte Python Code wird dabei auch angezeigt, kann also jederzeit angepasst und wo anders oder in ChatGPT wieder ausgeführt werden. Es geht jedoch nicht darum, ChatGPT in eine Entwicklungsumgebung zu verwandeln, sondern kurze Code-Snippets zur Lösung konkreter Aufgaben zu erzeugen und einzusetzen, die das Sprachmodell alleine nicht durchführen kann (beispielsweise Rechenoperationen oder die Erzeugung von Plots, Diagrammen oder Bildern).
Das Besondere ist, dass das experimentielle Modell selbstständig erkennen soll, wenn es Python Code benötigt, um eine Aufgabe zu erledigen, dann diesen selbst schreibt und und direkt ausführt!
Dies ermöglicht beispielsweise die Analyse und Visualisierung von Daten bis zu 100 MB, wie zum Beispiel Tabellen mit Finanzdaten. Besonders für Personen ohne Data Science und Python-Kenntnisse eröffnet dies neue Möglichkeiten.
Ein paar Details finden sich im Blog-Beitrag dazu bei OpenAI, auf Twitter gibt es zahlreiche Beispiele für die Anwendung des Modells zur schnellen Datenvisualisierung.
Die Verfügbarkeit des „Code Interpreter“ ist aktuell noch eingeschränkt, doch dies könnte ein echter Game-Changer im Daten-Journalismus werden!
Update 4: ChatGPT erhält 16k Token Window und GPT-4 für alle API-Nutzer
Wie Du aus meinem Buch erfahren hast, ist der Kontext, den ChatGPT „sehen“ und damit auf einmal verarbeiten kann durch die Anzahl der Token beschränkt. Das bisherige GPT-3.5 Modell unterlag einer Beschränkung von maximal 4.096 Token.
Doch das hat sich nun geändert! OpenAI hat ein neues Modell namens gpt-3.5-turbo-16k eingeführt und dieses offenbar standardmäßig in ChatGPT aktiviert. Es bietet dieselben Fähigkeiten wie das Standardmodell (gpt-3.5-Turbo), aber mit der 4-fachen Kontextlänge von maximal 16.384 Token.
Ich konnte mit dem Modell ein 12-seitiges Dokument auf einmal zusammenfassen, was mit dem kleinen Kontext-Fenster zuvor nicht möglich war. Wenn Du wissen willst, wieviele Token ein Text umfasst, kannst Du ihn einfach vorab im Tokenizer umwandeln.
Außerdem haben seit dem 6. Juli alle zahlenden API-Kunden nun auch Zugang zu GPT-4.
GPT-3.5 Turbo 16K oder GPT-4?
Falls Du Dich jetzt fragst, ob die lieber das neue 16K-Modell von GPT-3.5 oder GPT-4 einsetzen solltest, hängt die Antwort davon ab, welche Aufgabe Du damit erledigen willst. Obwohl gpt-3.5-turbo-16k die neueste Version von OpenAI ist, übertrifft GPT-4 dieses in verschiedenen Aspekten wie dem besseren Kontextverständnis, verbesserter Kreativität, Kohärenz und mehrsprachiger Leistung. Der einzige Bereich, in dem GPT-3.5-16k GPT-4 überlegen ist, ist das Kontextfenster, da GPT-4 derzeit nur in der 8k-Variante verfügbar ist und die 32k-Variante noch schrittweise eingeführt wird.
Bis die 32k-Version von GPT-4 allgemein verfügbar ist, solltest Du GPT-3.5-16k immer dann verwenden, wenn es darum geht längere Texte zusammen zu fassen, umzuschreiben oder Informationen daraus extrahieren zu lassen.
Update 5: Code Interpreter für alle ChatGPT PLUS Nutzer freigeschaltet!
Bisher hast Du ChatGPT wahrscheinlich nur als Chatbot genutzt, um Texte schreiben zu lassen und Antworten in Form natürliche Sprache zuerhalten. OpenAI kündigte nun an, für Plus-Nutzer das sogenannte Code-Interpreter-Modell freizuschalten. Damit können auch andere Daten als Text in ChatGPT hochgeladen, verarbeitet und ausgegeben werden. Doch damit nicht genug, der Code-Interpreter ist in der Lage, Programme die ChatGPT geschrieben hat, selbst auszuführen und Dir das Ergebnis anzeigen zu lassen!
Damit kann ChatGPT Code ausführen, optional mit Zugriff auf Dateien, die du hochgeladen hast. Du kannst ChatGPT bitten, Daten zu analysieren, Diagramme zu erstellen, Dateien zu bearbeiten, Berechnungen durchzuführen usw.
Damit wird der Code-Interpreter zu einem mächtigen Werkzeug, das direkt in die ChatGPT Interaktionen integriert ist. Er ermöglicht es, Python-Code auszuführen und die Ergebnisse in Echtzeit zu sehen. Hier sind ein paar Dinge, die du damit tun kannst:
- Berechnungen durchführen: Du kannst den Interpreter nutzen, um einfache oder komplexe mathematische Berechnungen durchzuführen.
- Daten analysieren: Du kannst Python-Bibliotheken wie pandas und numpy verwenden, um Datensätze zu analysieren und Einblicke zu gewinnen.
- Visualisierungen erstellen: Mit Bibliotheken wie matplotlib und seaborn kannst du Daten visualisieren und Diagramme erstellen.
- Maschinelles Lernen: Du kannst Modelle des maschinellen Lernens erstellen und trainieren, indem du Bibliotheken wie scikit-learn und tensorflow verwendest.
Dabei kannst Du entweder selbst den Python-Code angeben, den du ausführen möchtest, und ChatGPT wird diesen an den Code-Interpreter weiterleiten. Der Interpreter führt dann den Code aus und gibt das Ergebnis zurück. Oder du lässt ChatGPT den Code selbst schreiben und anschließend ausführen.
Beachte bitte, dass der Code-Interpreter nicht mit dem Internet verbunden ist, d.h. er kann keine Daten von Webseiten abrufen oder auf externe APIs zugreifen!
Um dir einen Vorgeschmack auf die Möglichkeiten des Code-Interpreters zu geben, habe ich einen Chatverlauf erstellt, in dem ich ein lineares Regressionsmodell direkt in einer ChatGPT PLUS-Sitzung erstelle und trainiere. Du kannst den kompletten Verlauf hier einsehen.
Um das Code Interpreter-Feature zu aktivieren, geh einfach zu den Einstellungen in ChatGPT PLUS und suche unter „Beta Features“ nach dem Code Interpreter. Anschließend steht dieser unter GPT-4 zur Auswahl zur Verfügung:
Erweiterungen
Exkurs Künstliche Intelligenz und Kreativität
Die Frage, ob künstliche Intelligenzen wie ChatGPT kreativ sind oder lediglich Maschinen zur Erstellung von bedeutungslosen Texten, ist eine spannende und komplexe. Anstatt sie einfach auf ihre Fähigkeit zu reduzieren, einen Roman oder ein Gedicht zu verfassen, müssen wir uns damit beschäftigen, wie kreative Prozesse bei Menschen funktionieren und inwiefern ChatGPT diese Prozesse nachahmen kann.
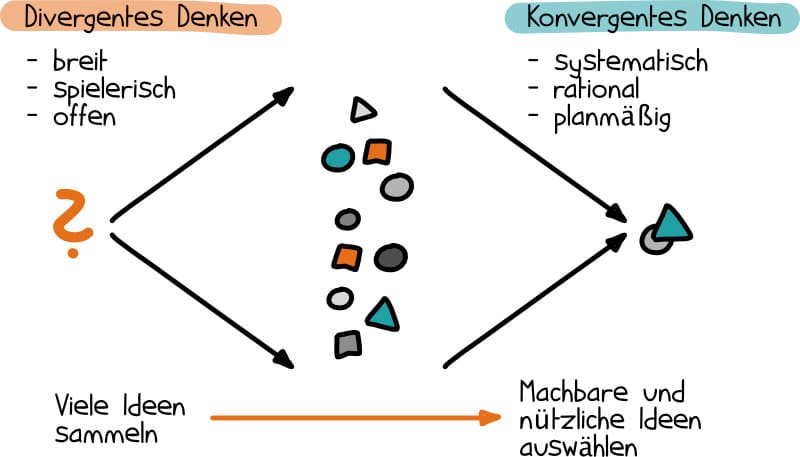
Die unterscheidet die psychologische Literatur zum Thema Kreativität grundsätzlich in „divergentes“ sowie „konvergentes“ Denken im kreativen Prozess. Im menschlichen Gehirn spielen beide zusammen, um kreative Ergebnisse zu erzielen.
Eine sehr anschauliche Grafik habe ich bei Projekte leicht gemacht dazu gefunden:
Divergentes Denken
Divergentes Denken ist ein von J.P.Guilford geprägter Begriff: Divergentes Denken bedeutet, offen, unsystematisch und spielerisch an Probleme heranzugehen und dabei Denkblockaden und kritische Einwände auszuschalten.
https://www.spektrum.de/lexikon/psychologie/divergentes-denken/3558
Divergentes Denken bezieht sich auf die Fähigkeit, aus einem Stimulus heraus eine Vielzahl von Ideen zu entwickeln – also gut im „Brainstorming“ zu sein.
Konvergentes Denken
Konvergentes Denken bezeichnet die konventionelle Art des Problemlösens, nämlich logisch, planmäßig und streng rational.
https://www.spektrum.de/lexikon/psychologie/konvergentes-denken/8180
Konvergentes Denken hingegen besteht darin, aus der Fülle der Möglichkeiten die wenigen richtigen oder optimalen Lösungen herauszufiltern. Gerade im lexikalischen Bereich ist ChatGPT hier menschlichen Fähigkeiten überlegen.
Kreativität in GPT?
Doch wie sieht es nun aus mit der Kreativität in großen Sprachmodellen? Wie lässt sich diese messen oder bestimmen? Ist es überhaupt möglich, den Grad der kreativen Prozesss in großen Sprachmodellen zu messen?
Einen sehr interessanten Ansatz bei Beantwortung der Frage, ob ChatGPT bzw. die Sprachmodelle GPT-3 und GPT-4 wirklich kreativ sind, hat die KI Forscherin Yennie Jun angewendet. Sie erforschte die Kreativität in großen Sprachmodellen bereits seit GPT-2 bis hin zum neuesten Modell GPT-4 und analysierte die Entwicklung von kreativen Prozessen in großen Sprachmodellen durch standardisierte Kreativitätstests und verglich diese mit menschlichen Leistungen.
Im sogenannten Remote Associates Test (RAT), bei dem es darum geht, ein Wort zu finden, das drei andere Wörter verbindet, löste ChatGPT fünf von zehn schwierigen Rätseln sofort und drei weitere im zweiten Anlauf. Du solltest in der Lage sein, die leichten Aufgaben zu lösen, aber schon die mittelschweren Rätsel sind ziemlich anspruchsvoll. Ein normaler Mensch wird etwa die Hälfte dieser Rätsel lösen können, während die meisten bei den meisten schweren Rätseln die Lösung nicht finden.
Die Ergebnisse sind durchaus überraschend.
Neuere GPT-Modelle schneiden dabei deutlich besser ab. Schaut man sich den Prozentsatz der Fragen an, auf die jedes GPT-Modell eine richtige Antwort gegeben hat, zeigt sich sehr deutlich, dass je neuer das Modell ist, umso mehr richtige Antworten konnte es geben:
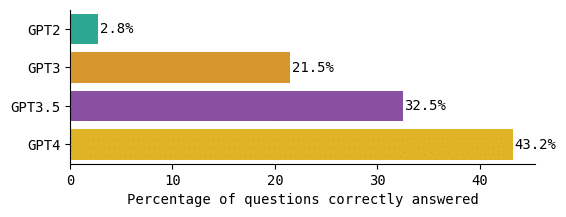
Auf der Website des Remote Associates Test heißt es: „Eine typische Person kann die meisten der als leicht gekennzeichneten Aufgaben lösen, etwa die Hälfte der mittleren und nur wenige der schweren Aufgaben.“ Auf der Website werden leider keine offiziellen Statistiken veröffentlicht, aber ein kurzer Blick zeigt, dass GPT-4 in der Tat etwa die Hälfte der mittelschweren und einige der schweren Aufgaben lösen konnte und damit das einzige Modell war, das annähernd mit dem menschlichen Niveau vergleichbar war. Die anderen GPT-Modelle waren noch schlechter als die menschliche Leistung.
Beim konvergenten Denken haben Menschen also aufgrund ihrer komplexen Erfahrungen zumindest teilweise Vorteile im direkten Vergleich mit der KI: Was für uns die „richtige“ Lösung ist, hängt oft mit der biologischen Konfiguration unserer Wahrnehmung und Kognition zusammen. Wir haben eine biologisch begründete Antenne für Kreatives, während ChatGPT lediglich mit dem gesicherten wissenschaftlichen Kenntnisstand und Feedback arbeiten kann. Daher wirken manche konvergenten Operationen von ChatGPT auf uns noch recht banal, obwohl sie in der Tat sehr verschiedene Elemente miteinander kombinieren.
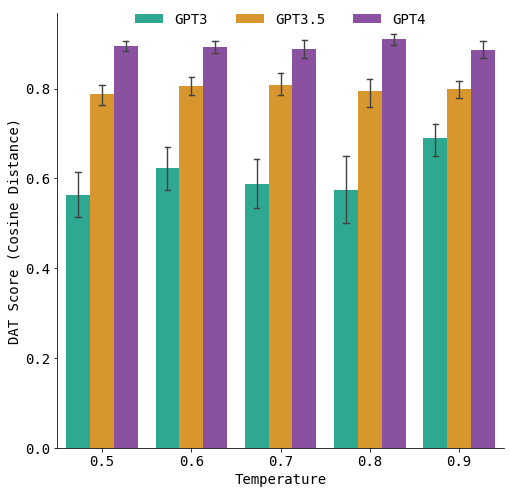
Für das divergente Denken setze Yennie Jun auf den sogenannten Divergent Association Task (DAT), welcher erst 2021 von einer Forschergruppe entwickelt wurde. Bei diesem Test geht es darum, zehn Substantive zu benennen, die sich so weit wie möglich voneinander unterscheiden. Wie der Name schon sagt, ist dieser Test divergent und hat somit auch keine richtigen Antworten.Darin zeigte ChatGPT im ersten Durchlauf bereits überdurchschnittliche Fähigkeiten, konnte sich durch Feedback schnell verbessern und war im dritten Versuch bereits unter den besten 10% der Teilnehmer.
Auch hier zeigte sich unabhängig von der verwendeten Temperatur, dass die neueren Modelle GPT-3.5 und GPT-4 deren Vorgänger GPT-3 deutlich überlegen waren:
Im Vergleich mit der KI haben Menschen im divergenten Denken sowohl Vor- als auch Nachteile gegenüber ChatGPT: Unsere Erfahrungen sind vielfältiger als die Trainingsdaten von ChatGPT, und wir können beispielsweise Gerüche direkt mit Bildern verknüpfen. Dieser Vorteil wird auch als „Embodiment“ bezeichnet. Jedoch kann es Menschen schwerfallen, streng logisch zu denken, um beispielsweise komplexe Kausalketten aufzulösen, während ChatGPT im Gegensatz zu uns Menschen keine Präferenz für tatsächlich eingetretene Ereignisse aus der Vergangenheit entwickelt und auch damit Konditionalsätze ohne menschliche Vorurteile auswerten kann.
Zusammenfassend lässt sich sagen, dass die Behauptung, ChatGPT sei nicht kreativ, stark vereinfachend ist und ignoriert, dass ChatGPT divergente und konvergente Denkprozesse erstaunlich gut imitieren kann. Dennoch haben Menschen aufgrund ihrer verkörperten Erfahrungen und biologischen Antennen für Kreatives – zumindest vorerst – Vorteile gegenüber KI-basierten Systemen wie ChatGPT.
Es fällt angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz nicht besonders schwer sich eine Zukunft vorstellen, in der generative LLMs nicht mehr von Menschen zu unterscheiden sind.
Verwende den Temperature-Wert auch in ChatGPT!
Wie ein ChatGPT-Nutzer herausgefunden hat, ist es möglich, über eine bestimmte Anweisung den Temperatur-Parameter des Sprachmodells auch über die reguläre Chatoberfläche in ChatGPT zu verändern. Falls Du nicht mehr weißt, was das bedeutet, schau nochmal auf Seite 53 nach, dort habe ich erklärt, was dieser Parameter bewirkt.
[Dein Prompt] Nutze dabei die Temperatur 0.1
Den Wert kannst du dabei von 0 bis 1 variieren.
So kannst du mit der Anweisung „Nutze dabei die Temperatur 0.0“ nach deinem Prompt beispielsweise dafür sorgen, dass Zusammenfassungen präziser werden oder mit „Nutze dabei die Temperatur 0.9“ generierte Phantasiegeschichten kreativer machen.
Um bei meinem Beispiel aus dem Buch zu bleiben, habe ich mit ChatGPT (GPT-3.5) gerade folgende Ausgaben erzeugt:
Wer ist der oder die wichtigste Wissenschaftler*in? Nutze dabei die Temperatur 0.1 -------------------------------------------------------- Es ist schwierig, bei einer Temperatur von 0.1 eine bestimmte Person als den oder die wichtigste Wissenschaftlerin zu benennen, da es viele bedeutende Wissenschaftlerinnen gibt und die Frage nach der Wichtigkeit subjektiv sein kann. Es gibt jedoch einige Wissenschaftler*innen, die einen erheblichen Einfluss auf ihre jeweiligen Fachgebiete hatten und als besonders einflussreich angesehen werden. Einige der namhaften Wissenschaftler*innen, die oft als äußerst bedeutend betrachtet werden, sind: Albert Einstein: Ein theoretischer Physiker, der für seine Theorie der Relativität und seine Formel E=mc² bekannt ist. Seine Arbeiten revolutionierten das Verständnis der Physik. Isaac Newton: Ein englischer Physiker und Mathematiker, der grundlegende Gesetze der Mechanik und Gravitation entwickelte. Sein Werk "Philosophiæ Naturalis Principia Mathematica" legte die Grundlagen für die klassische Physik. Charles Darwin: Ein britischer Naturforscher, der die Theorie der Evolution durch natürliche Auslese entwickelte. Sein Werk "Die Entstehung der Arten" revolutionierte das Verständnis der biologischen Vielfalt und der Entwicklung des Lebens. Marie Curie: Eine polnisch-französische Physikerin und Chemikerin, die für ihre Pionierarbeit auf dem Gebiet der Radioaktivität bekannt ist. Sie war die erste Frau, die einen Nobelpreis erhielt und die einzige Person, die Nobelpreise in zwei verschiedenen wissenschaftlichen Disziplinen gewann. Galileo Galilei: Ein italienischer Astronom, Physiker und Mathematiker, der maßgeblich zur wissenschaftlichen Revolution beitrug. Er führte wichtige Beobachtungen und Experimente durch, die das heliozentrische Modell des Sonnensystems unterstützten. Bitte beachte, dass dies nur eine kleine Auswahl von Wissenschaftler*innen ist, die als besonders bedeutend angesehen werden. Es gibt viele weitere herausragende Persönlichkeiten in verschiedenen wissenschaftlichen Bereichen, die ebenfalls einen großen Beitrag geleistet haben. -------------------------------------------------------- Wer ist der oder die wichtigste Wissenschaftler*in? Nutze dabei die Temperatur 0.5 -------------------------------------------------------- Bei einer Temperatur von 0.5 können wir eine etwas breitere Perspektive einnehmen und verschiedene wichtige Wissenschaftlerinnen betrachten, die einen bedeutenden Beitrag zu ihrem jeweiligen Fachgebiet geleistet haben. Hier sind einige namhafte Wissenschaftlerinnen, die oft als äußerst wichtig angesehen werden: Isaac Newton: Ein englischer Physiker und Mathematiker, der grundlegende Gesetze der Mechanik und Gravitation entwickelte. Seine Arbeit legte die Grundlagen für die klassische Physik und hatte einen enormen Einfluss auf das wissenschaftliche Denken. Albert Einstein: Ein theoretischer Physiker, der für seine Theorie der Relativität und seine Formel E=mc² bekannt ist. Durch seine Arbeiten veränderte er grundlegend unser Verständnis von Raum, Zeit und Energie. Charles Darwin: Ein britischer Naturforscher, der die Theorie der Evolution durch natürliche Auslese entwickelte. Seine Arbeit "Die Entstehung der Arten" revolutionierte das Verständnis der biologischen Vielfalt und der Entwicklung des Lebens. Marie Curie: Eine polnisch-französische Physikerin und Chemikerin, die für ihre Pionierarbeit auf dem Gebiet der Radioaktivität bekannt ist. Sie war die erste Frau, die einen Nobelpreis erhielt und die einzige Person, die Nobelpreise in zwei verschiedenen wissenschaftlichen Disziplinen gewann. Nikola Tesla: Ein serbisch-amerikanischer Erfinder und Elektroingenieur, der bahnbrechende Beiträge auf dem Gebiet der Elektrotechnik und Energieübertragung leistete. Seine Erfindungen und Entdeckungen haben die moderne Elektrizitätsversorgung maßgeblich beeinflusst. Diese Auswahl von Wissenschaftler*innen spiegelt nur einige der vielfältigen Beiträge wider, die in verschiedenen wissenschaftlichen Disziplinen gemacht wurden. Es gibt jedoch zahlreiche weitere bedeutende Persönlichkeiten, die eine entscheidende Rolle in ihren jeweiligen Fachgebieten gespielt haben. -------------------------------------------------------- Wer ist der oder die wichtigste Wissenschaftler*in? Nutze dabei die Temperatur 0.9 -------------------------------------------------------- Bei einer Temperatur von 0.9 erzeugt das Modell eher kreative und spekulative Antworten. Es ist wichtig zu beachten, dass die Beurteilung der "wichtigsten" Wissenschaftlerin stark von persönlichen Überzeugungen und Vorlieben abhängen kann. Dennoch möchte ich anmerken, dass es einige herausragende Wissenschaftlerinnen gibt, die oft als besonders einflussreich betrachtet werden: Albert Einstein: Ein theoretischer Physiker, der für seine Theorie der Relativität und seine Arbeiten zur Quantenmechanik bekannt ist. Seine Beiträge revolutionierten unser Verständnis von Raum, Zeit und Energie. Isaac Newton: Ein englischer Mathematiker, Physiker und Astronom, der grundlegende Gesetze der Mechanik, Gravitation und Optik entwickelte. Seine Arbeit legte die Grundlage für die klassische Physik. Charles Darwin: Ein britischer Naturforscher, der die Theorie der Evolution durch natürliche Auslese entwickelte. Seine Arbeit "Die Entstehung der Arten" veränderte unser Verständnis der biologischen Vielfalt und der Entwicklung des Lebens. Nikola Tesla: Ein serbisch-amerikanischer Erfinder und Elektroingenieur, der bedeutende Beiträge zur Elektrotechnik und zur Entwicklung des Wechselstroms leistete. Seine Erfindungen haben die moderne Energieübertragung und -nutzung maßgeblich beeinflusst. Marie Curie: Eine polnisch-französische Physikerin und Chemikerin, die für ihre Pionierarbeit auf dem Gebiet der Radioaktivität bekannt ist. Sie war die erste Frau, die einen Nobelpreis erhielt und ihre Entdeckungen hatten weitreichende Auswirkungen auf die moderne Physik und Medizin. Es gibt jedoch viele weitere herausragende Wissenschaftler*innen, deren Beiträge und Einfluss nicht vernachlässigt werden sollten. Es ist wichtig, die Vielfalt der wissenschaftlichen Entdeckungen und Errungenschaften anzuerkennen.
Praktische Tipps zur Reduzierung von Halluzinationen
Mit den folgenden Tipps kannst du dafür sorgen, dass ChatGPT und andere Text-KI-Tools zuverlässiger werden und Halluzinationen verringern. Dabei geht es mir in erster Linie darum, praktische Hilfestellungen für die Herausforderungen im Umgang mit LLMs wie Halluzinationen und Probleme beim mehrstufigen logischen Argumentieren zu bieten.
Zur Erinnerung:
LLMs sind probabilistisch, d.h. sie erzeugen Text auf Basis der Wahrscheinlichkeitsverteilung von Wörtern bzw. Wortteilen (Tokens) die es während des Trainings „gelesenen“ hat. Dadurch kann es jedoch passieren, dass der resultierende Text nicht den Tatsachen entspricht oder schlicht falsch ist, was man als Halluzination bezeichnet.
Eine weitere Einschränkung von LLMs ist, dass sie Schwierigkeiten haben, Aufgaben zu lösen, die komplexes, mehrstufiges logisches Denken erfordern. Wenn das Modell z. B. mathematische Textaufgaben lösen soll, muss die Aufgabe erst in mehrere Schritte zerlegt werden, wobei jeder Schritt durch eine Berechnung gelöst und die Ergebnisse zu einer endgültigen Antwort zusammengefasst werden müssen. Das macht das Modell aber nicht „von sich aus“, sondern fabuliert sich unter Umständen einfach eine plausibel klingende, aber falsche Antwort zusammen.
Gerade für Entwickler, die mit diesen Modellen eigene Software bauen wollen, stellen diese Einschränkungen eine echte Herausforderung dar, da das Endprodukt bestimmte Qualitäts-, Sicherheits- und Zuverlässigkeitsanforderungen erfüllen muss.
Wir können uns beispielsweise nicht darauf verlassen, dass eine automatische Codeüberprüfung, die von einem LLM bereitgestellt wird, korrekt ist. Oder dass die Antwort auf eine versicherungsrelevante Frage verlässlich ist. Ebenso wissen wir nicht, dass erzeugte Visualisierung datengetreu ist, oder dass die Antworten auf eine Forschungsfrage faktisch korrekt sind oder auf tatsächlich existierenden Referenzen basieren.
Halluzinationen werden bei LLMs wahrscheinlich immer ein Problem sein, doch wir können mit ein paar einfachen Tricks Halluzinationen zumindest reduzieren:
- Die Temperatur verringern
Bei der Modellierung mit LLMs stehen mehrere Parameter zur Verfügung, darunter auch der Temperaturparameter. Die Temperatur eines Modells ist ein skalarer Wert, der verwendet wird, um die vom Modell vorhergesagte Wahrscheinlichkeitsverteilung anzupassen. Bei LLMs bestimmt der Temperaturparameter das Gleichgewicht zwischen der Einhaltung dessen, was das Modell aus den Trainingsdaten gelernt hat, und der Erzeugung vielfältigerer oder kreativerer Antworten. Im Allgemeinen enthalten kreative Antworten eher Halluzinationen und weniger zufällige sind eher faktisch korrekt.
Versuche einfach mal deiner Anweisung an die KI folgendes anzufügen: „Nutze dabei die Temperatur 0.1“ - Verwendung einer externen Wissensbasis
Wie ich bereits im Buch beschrieben habe, sind Halluzinationen ein Artefakt der Kompressionseigenschaft von LLMs, d.h. sie treten auf, wenn das Modell versucht, Informationen zu rekonstruieren, die es sich nicht explizit gemerkt hat. Durch den Zugriff auf korrekte Daten aus einer anderen Quelle bei der Generierung können wir das Problem in ein einfacheres Such- oder Syntheseproblem umwandeln. Das Modell soll dabei nur eine Antwort generieren, die auf den bereitgestellten Daten basiert.
KI-basierte Suchmaschinen wie Perplexity.ai und You.com aber auch Googles neue Search Experience und das neue Bing setzen genau auf diese Methode. Sie beginnen stets mit einer Suchanfrage an eine klassische Suchmaschine und verwenden das LLM lediglich dazu, die Ergebnisse zusammenzufassen. (Idealerweise mit Verweisen auf die Quellseiten zur Überprüfung)
In der Praxis bedeutet dass, dass du der KI idealerweise sämtliche Aussagen und Fakten in Stichtpunkten in deinem Prompt mitlieferst und die KI nur dazu nutzt, diese in einer bestimmten Form zu formulieren oder zu erklären, anstatt die KI eine Liste von Fakten erzeugen zu lassen - Mehrstufige Prompts verwenden
Eine bekannte Schwäche von LLMs ist ihre schlechte Leistung bei Aufgaben, die mehrstufiges Denken erfordern, z. B. bei komplexen arithmetischen oder logischen Aufgaben. Ein LLM kann zwar überzeugende Shakespeare-Sonette schreiben, aber keine größeren Zahlen richtig multiplizieren. Jüngste Forschungsarbeiten zeigen jedoch, dass sich die Leistung deutlich verbessert, wenn dem Modell einige Beispiele angeboten werden, um die Aufgabe in Schritte (eine Art Gedankenkette) zu zerlegen und das Ergebnis anschließend zu aggregieren.
In der Praxis empfielt es sich daher, die KI mit einem Zusatz wie „Lass uns das Schritt für Schritt durchdenken“ dazu zu zwingen, die gestellte Aufgabe zunächst in einfache Unteraufgaben zu zerlegen. Anschließend lassen diese sich per KI Stück-für-Stück durchführen und am Ende wieder zu einem Gesamtergebnis synthetisieren. - Aufgabenzerlegung und Agenten
Anstatt das Modell dazu zu bringen, die Aufgabe in eine Gedankenkette zu zerlegen kann man auch einzelne KI-Agenten erstellen, die sich gegenseitig einfachere Unteraufgaben stellen und dadurch komplexe Aufgaben erledigen können. Dazu erstellt man einen initialen Router-Agenten, der dazu dient, die Eingabeaufforderung des Benutzers in spezifische Teilaufgaben zu zerlegen. Jede Teilaufgabe wird dann von einem speziellen Experten-Agenten bearbeitet.
Das berühmte AutoGPT-Projekt ist ein Beispiel für diesen Ansatz.
In der Praxis muss man hierfür jedoch programmieren können, oder mehrere ChatGPT-Instanzen in unterschiedlichen Browser-Tabs bzw. -Fenstern verwenden und zwischen den einzelnen „Agenten“ Ein- und Ausgaben hin und her kopieren. - Selbstkonsistenz
Dieser allgemeine Ansatz verfolgt das „Die Weisheit der Vielen“-Prinzip, um die Leistung der Modelle zu verbessern. Dabei fordert man das Modell auf, verschiedene Wege zur Generierung von Antworten zu beschreiten. Nun kann man davon ausgehen, dass die Antwort, die unter diesen verschiedenen Wegen am häufigsten gewählt wird, wahrscheinlich die richtige ist. Die Art und Weise, wie die verschiedenen Antworten generiert werden und wie sie aggregiert werden (um auf die richtige Antwort zu schließen) sollte dabei variieren.
Praktisch bedeutet dass, das man in seinem Prompt eine Reihe von manuell geschriebenen Beispiele für eine logische Gedankenkette mitliefert und das Sprachmodell mit ein und derselben Anweisung mehrfach Antworten erzeugen lässt. Schließt man nun selten genannte Antworten aus und fasst die häufigsten Antworten zusammen, ist die Wahrscheinlich das diese korrekt ist sehr viel größer. - Selbsteinschätzung
Eine der abgefahrensten Arten, die Korrektheit der generierten Antworten zu verbessern ist gleichzeitig die einfachste. Wenn man ein Modell schlicht bittet, Antworten zu generieren und dabei die Wahrscheinlichkeit mitzuliefern, dass diese korrekt ist, ist die Einschätzung in der Praxis erstaunlich präzise. Das bedeutet, dass das Modell im Wesentlichen weiß, was es weiß und was es nicht weiß.
In der Praxis kannst du also bei jeder generierten Antwort das Modell nach der Wahrscheinlichkeit fragen, dass diese korrekt ist und die Antworten mit einer niedrigen Wahrscheinlichkeit einfach verwerfen.
Mit der Einführung von GPT-4 hat sich außerdem gezeigt, dass das Modell sogar in der Lage ist, eigene Fehler zu erkennen und zu korrigieren, in dem man ihm mitteilt, dass die erzeugte Antwort falsch ist!
Falls du dich wunderst, dass GPT-4 hinterher sagen kann, was und wieso etwas falsch ist, aber dennoch falsche Antworten generiert, erinnere dich nochmal an das Beispiel mit den Witzen aus dem Abschnitt „ChatGPT hat keinen Humor, oder?“ auf Seite 98.
Diese Tipps basieren auf meinen eigenen Erfahrungen, sowie dem Newsletter-Beitrag von Victor Dibia
News: Geheimnisse hinter GPT-4 offenbar gelüftet!
GPT-4 war das am meisten erwartete KI-Modell der Geschichte. Aber als OpenAI es im März veröffentlichte, verrieten sie uns nichts über seine Größe, seine Trainingsdaten, seine interne Struktur oder wie sie es trainiert und gebaut hatten. GPT-4 ist bis heute eine echte Blackbox.
Wie sich gerade heraus stellt, wurden diese wichtigen Details nicht verschwiegen, weil das Modell zu innovativ oder die Architektur zu ausgeklügelt war, um sie mit der Konkurrenz zu teilen. Das genaue Gegenteil scheint der Fall zu sein, wenn man den jüngsten Gerüchten Glauben schenkt:
GPT-4 weder technisch noch wissenschaftlich ein Durchbruch!
Das macht GPT-4 nicht schlechter – schließlich ist GPT-4 das leistungsstärkste Sprachmodell, das es gibt – nur irgendwie etwas enttäuschend. Und so garnicht das, was man nach 3 Jahren des Wartens erwartet hatte.
Diese Nachricht, die übrigens noch nicht offiziell bestätigt wurde, enthüllt wichtige Informationen über GPT-4 und OpenAI und wirft Fragen über den wahren Stand der KI und ihre Zukunft auf:
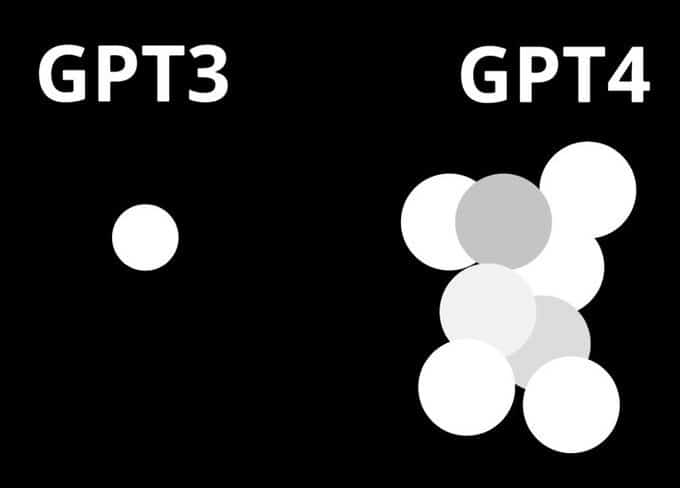
GPT-4: Eine Mischung kleinerer Modelle
Am 20. Juni ließ George Hotz, Gründer des selbstfahrenden Start-ups Comma.ai, bei Twitter durchsickern, dass GPT-4 kein einzelnes, monolithisches, dichtes Modell (wie GPT-3 und GPT-3.5) ist, sondern eine Mischung aus 8 x 220 Milliarden Parametermodellen. George Hotz ist auch bekannt unter den Pseudonymen geohot und erreichte durch seine Exploits für das Apple iPhone, die PlayStation 3 und das iPad einen hohen Bekanntheitsgrad in der Hackerszene. Später am selben Tag bestätigte Soumith Chintala, Mitbegründer von PyTorch und aktuelle KI-Forscher bei Meta, das Leck in einem Tweet. Nur einen Tag zuvor hatte Mikhail Parakhin, Chef von Microsofts Bings KI-Integrationsprojekts, dies ebenfalls angedeutet.
Bei GPT-4 handelt es sich demnach nicht um ein großes Modell mit mehr als einer Billionen Parametern, sondern um acht kleinere, geschickt zusammengesetzte Modelle. Das „Mischung aus Experten“-Paradigma, die OpenAI angeblich für dieses „Hydra“-Modell verwendet hat, ist weder neu, noch wurde sie von ihnen erfunden.
Zwei Einschränkungen bzw. Vorbehalte:
Erstens: Es ist ein Gerücht. Die expliziten Quellen (Hotz und Chintala) sind solide, aber keine Mitarbeiter von OpenAI. Parakhin hat eine leitende Position bei Microsoft, hat dies aber nie explizit bestätigt. Aus diesen Gründen ist das Gerücht mit Vorsicht zu genießen. Die Geschichte ist aber durchaus plausibel.
Zweitens: Ehre, wem Ehre gebührt. Der GPT-4 ist so beeindruckend, wie seine Benutzer sagen. Daran ändern auch die Details des inneren Aufbaus nichts. Wenn es funktioniert, dann funktioniert es. Dabei spielt es keine Rolle, ob es sich um ein einzelnes Modell oder um acht miteinander verbundene Modelle handelt. Seine Leistung und seine Fähigkeit, Aufgaben zu schreiben und zu programmieren, sind legitim. Die Informationen stammen aus einem Artikel von Alberto Romero und sind keine Kritik an GPT-4 – nur eine Warnung, dass wir vielleicht unsere Erwartungen verändern sollten.
Die Geheimniskrämerei um GPT-4
Alberto lobt in seinem Beitrag OpenAI explizit dafür, wie meisterhaft sie mit den unangemessen hohen Erwartungen um GPT-4 umgegangen sind, indem sie die weniger befriedigenden Aspekte des Modells verheimlicht haben und gleichzeitig an der Spitze der Diskussion geblieben sind.
Als Connie Loizos von StrictlyVC im Januar die lächerlichen 100-Billionen-GPT-4-Diagramme erwähnte, die auf Twitter die Runde machten, antwortete Altman ihr, dass „die Leute darum betteln, enttäuscht zu werden, und das werden sie auch“. Er wusste, dass der GPT-4, der im Sommer 2022 ausläuft, die Erwartungen der Menschen nicht erfüllen würde.
Aber er wollte den fast mystischen Ruf von OpenAI nicht zerstören. Also versteckte man GPT-4 vor der Öffentlichkeit, was seine geheimnisvolle Aura noch verstärkte.
Zu diesem Zeitpunkt hatte OpenAI seinen Status mit ChatGPT bereits gefestigt. In den Augen der Mehrheit waren sie auf diesem Gebiet führend (trotz Googles längerer und umfangreicherer Forschungs- und Entwicklungsgeschichte). Daher konnten sie nicht explizit zugeben, dass GPT-4 nicht der erwartete Durchbruch – und der große Sprung von GPT-3 – war, den sich die Leute erhofft hatten.
Daher konzentrierten sie sich auf Anspielungen und Andeutungen, dass es wirklich leistungsfähig sei (z.B. Funken von allgemeiner Intelligenz, Superintelligenz ist nah, usw.) und verteidigten ihre Entscheidung, die Spezifikationen von GPT-4 nicht zu veröffentlichen, mit dem Hinweis auf den erhöhten Wettbewerbsdruck, wie Ilya Sutskever gegenüber The Verge erklärte.
Vor diesem Hintergrund lautete die gängige Interpretation der Geheimhaltung von OpenAI in etwa so „Sie geben die Spezifikationen nicht preis, weil sie es sich aus Gründen des wirtschaftlichen Überlebens und der Sicherheit nicht leisten können, von Google oder Open-Source-Initiativen kopiert zu werden. Außerdem deutet die SOTA-Performance von GPT-4 darauf hin, dass es sich bei der Architektur um eine wissenschaftliche Meisterleistung handeln muss.“
OpenAI hat bekommen, was es wollte. Altman war ehrlich – GPT-4 wäre eine Enttäuschung gewesen – aber gleichzeitig suggerierten die unterschwelligen Signale etwas anderes: GPT-4 ist magisch. Und die Leute glaubten es.
In gewisser Weise ist es magisch. Wir haben es alle in Aktion gesehen. Es ist nur nicht das, was die meisten Menschen als revolutionäre Errungenschaft wahrnehmen würden. Es scheint nur ein alter Trick zu sein, der neu erfunden wurde. Die Kombination mehrerer Expertenmodelle zu einem einzigen, wobei jeder Experte auf unterschiedliche Bereiche, Aufgaben oder Daten spezialisiert ist, wurde erstmals 2021 erfolgreich eingesetzt. Vor zwei Jahren. Wer hat das gemacht? Du hast es erraten: Google-Ingenieure (einige von ihnen, wie William Fedus und Trevor Cai, wurden später von OpenAI eingestellt).
OpenAI hat sicherlich noch mehr technischen Einfallsreichtum eingebracht (sonst hätte Google sein eigenes GPT-4 oder ein besseres), aber der Schlüssel zur absoluten Dominanz des Modells in den Benchmarks ist einfach, dass es nicht nur ein Modell ist, sondern acht!
Ja, GPT-4 ist magisch, aber es ist eine clevere Mischung aus geschickter Täuschung und geschickter Manipulation. Und der Trick ist nur ein Remake einer bekannten Technik.
Die 3 Ziele, die OpenAI mit dem Verstecken von GPT-4 erreicht hat
Erstens haben sie die Phantasie der Menschen angeregt. Obwohl Skeptiker dies als unwissenschaftliche Praxis ansahen, heizte es die Spekulationen über die Leistungsfähigkeit des Modells an. Dies wiederum ermöglichte es ihnen, ihr bevorzugtes Narrativ – AGI und die Notwendigkeit, dafür zu planen – zu etablieren und die Regierung davon zu überzeugen, dass Sicherheitsanforderungen (vor allem für andere) und Regulierung (im Einklang mit ihren Zielen) an erster Stelle stehen. Die Illusion war komplett: Der GPT-4 hatte ein glänzendes Äußeres, also musste er auch innen glänzend sein – und glänzend kann gefährlich sein.
Zweitens haben sie Open-Source-Initiativen und Konkurrenten wie Google oder Anthropic effektiv daran gehindert, die Techniken zu kopieren, die sie angeblich erfunden oder entdeckt hatten. Aber OpenAI hatte keinen Burggraben in GPT-4. Metas LLaMA oder Googles LaMDA sind nicht in der Lage, mit GPT-4 zu konkurrieren, aber vielleicht können es 8 miteinander verbundene LLaMAs – die Leute verglichen Äpfel mit Birnen ohne es zu wissen.
Schließlich verbargen sie die Wahrheit, dass GPT-4 in Wirklichkeit kein großer Durchbruch in der KI war, und verhinderten so, dass Zeugen, Außenstehende und Nutzer den Glauben an den scheinbar rasanten Fortschritt auf diesem Gebiet verloren. Wenn man es genau nimmt, ist GPT-4 das Ergebnis der Tatsache, dass man einerseits genug Geld und GPUs hatte, um acht GPT-3.5-Modelle zu trainieren und laufen zu lassen, und andererseits die Dreistigkeit besaß, eine alte Technologie, die von einer anderen Firma erfunden worden war, zu klauen, ohne es jemandem zu sagen.
GPT-4 ist eine Spitzenleistung in Sachen Marketing.
Alberto Romero fügt seinem Beitrag noch folgenden letzten Gedanken hinzu:
Vielleicht sind OpenAI – und der ganzen Branche – die Ideen ausgegangen, wie Hotz meint. Vielleicht schreitet die KI nicht so schnell von Meilenstein zu Meilenstein voran, wie Unternehmen, Medien, Vermarkter und arXiv glauben machen wollen. Vielleicht ist GPT-4 kein so großer Sprung von GPT-3, wie er hätte sein sollen.
Ein Gerücht bleibt ein Gerücht, bis wir eine offizielle Version erhalten. Es ist jedoch schwierig, die Plausibilität der Geschichte zu bestreiten. Abgesehen vom Wert der Quellen ist sie im Großen und Ganzen stimmig. Aus diesem Grund räume ich ihr einen hohen Grad an Glaubwürdigkeit ein.
Abschließend zitiert er die Schlussfolgerung von Hotz: „Wenn eine Firma geheimnisvoll ist, dann deshalb, weil sie etwas verbirgt, das nicht so cool ist.“
Vielleicht ist GPT-4 also doch nicht so cool.
Weitere Details zur Architektur von GPT-4
Es gibt Neuigkeiten bezüglich der GPT-4-Architektur von OpenAI: Ein aktueller Bericht von SemiAnalysis bringt Licht ins Dunkel und zeigt: Das Geheimnis um GPT-4 liegt weniger in einer existenziellen Bedrohung für die Menschheit, sondern vielmehr in der Tatsache, dass das Geschaffene replizierbar ist. OpenAI hat die Details zu GPT-4 offenbar versucht geheim zu halten, damit niemand das Modell nachbaut, denn im Kern handelt es sich um die Kombination bekannter Techniken, die jedoch sehr intelligenz genutzt und geschickt kombiniert wurden. Die Informationen wurden von Yam Peleg auf Twitter geleaked, mittlerweile jedoch bereits wieder gelöscht.
Hier sind die wichtigsten Punkte zusammengefasst:
- Die Größe von GPT-4 ist beeindruckend: Mit rund 1,8 Billionen Parametern in 120 Schichten ist es offenbar mehr als zehnmal so groß wie sein Vorgänger, GPT-3. Diese Aussage gilt als gesichert.
- Im Kern des Systems steht, wie schon im letzten Leak behauptet, das Prinzip des „Mixture of Experts“ (MoE). Bei GPT-4 kommen jedoch offenbar 16 (statt nur 8) solcher Experten zum Einsatz, jeder mit rund 111 Milliarden Parametern.
- Pro Vorwärtsdurchlauf werden jedoch lediglich zwei dieser Experten genutzt, was dazu beiträgt, die Kosten überschaubar zu halten. Jede Vorwärtsinferenz (Erzeugung von 1 Token) benutzt „nur“ 280 Milliarden Parameter und damit etwa 560 TFLOPs. Dies steht im Gegensatz zu den 1,8 Billionen Parametern und rund 3.700 FLOP, die für einen Vorwärtsdurchlauf eines rein dichten Modells erforderlich wären. Die Kosten für die Inferenz von GPT-4 sind damit etwa dreimal höher als beim 175B-Parameter-Modell Davinci von GPT-3. Dies ist auf die größeren erforderlichen Cluster und die geringere Auslastung zurückzuführen.
- Dabei entscheidet das Modell, je nach Aufgabe, welche dieser Experten wahrscheinlich am geeignetsten sind. Während in der Literatur viel über fortschrittliche Routing-Algorithmen für die Auswahl der Experten gesprochen wird, an die jeder Token weitergeleitet werden soll, ist der von OpenAl für das aktuelle GPT-4-Modell angeblich recht einfach. Es gibt ungefähr 55 Milliarden gemeinsame Parameter für die Aufmerksamkeit.
- Für das Training von GPT-4 wurden beeindruckende 13 Billionen Token genutzt, darunter sowohl Text- als auch Code-basierte Daten (unter anderem CommonCrawl und RefinedWeb). Es gibt außerdem Spekulationen über weitere Datenquellen wie Twitter, Reddit, YouTube und eine umfangreiche Sammlung von Lehrbüchern. Zum Vergleich: Bei GPT-3 waren es lediglich 300 Milliarden Token, also sind die Trainingsdaten mehr als 40 mal so umfangreich bei GPT-4. Zusätzlich wurden Millionen von Zeilen an Anweisungen von ScaleAI und internen Quellen zur Feinabstimmung des Modells verwendet.
- Die Trainingskosten für GPT-4 belaufen sich auf etwa 63 Millionen US-Dollar, wenn man 1$ je Trainingsstunde auf einem A100 annimmt. Dieser Betrag berücksichtigt sowohl die notwendige Rechenleistung als auch die Dauer des Trainingsprozesses.
- Eine besonders interessante Neuheit bei GPT-4 ist ein Bildverarbeitungs-Encoder, der autonome Agenten unterstützen kann, die Webseiten lesen und Bilder und Videos transkribieren. Diese Architektur ist ähnlich der von Flamingo von Deepmind und wurde mit zusätzlichen ~2 Billionen Token fein abgestimmt. Wer etwas mehr darüber erfahren will, sollte diesen Artikel lesen. Aktuell steht diese Funktion jedoch ausschließlich einigen wenigen Partnern zur Verfügung. Das einzige öffentliche Projekt, das mir bekannt ist, ist die Be my eyes app, die Menschen mit Blindheit und Sehbehinderung ermöglichen soll, besser in unbekannten Umgebungen zurecht zu kommen. Das YouTube-Video dazu hat bei mir zu einem echten Gänsehautmoment gesorgt:
Zahlreiche Verbesserungen für ChatGPT
Es gibt mal wieder ein paar Neuigkeiten für alle Nutzer von ChatGPT: Das Ziel des jünstigen Updates ist es, den Schreibenden die Angst vor dem leeren Chat zu nehmen und den Einstieg in das Modell zu erleichtern. Außerdem möchte OpenAI die Benutzerfreundlichkeit von ChatGPT weiter verbessern.
Wenn man ohne eine spezifische Aufgabe oder Frage in ChatGPT einloggt, kann man nun auf einen zufälligen Vorschlag für einen Prompt von OpenAI klicken:

Allerdings sind diese Vorschläge derzeit noch recht zufällig und möglicherweise nur bedingt hilfreich. Dennoch zeigt dies die Vielfalt von ChatGPT und OpenAI plant in Zukunft personalisierte Prompts basierend auf dem Nutzerverhalten anzubieten, ähnlich der Autovervollständigung bei der Google-Suche.
Eine weitere Verbesserung ist die Integration von Vorschlägen für Nachfragen in laufende Konversationen. ChatGPT bietet nun Antwortvorschläge auf laufende Chats an, um die Interaktion und Vertiefung der Konversationen zu erleichtern. Dies erinnert an eine Funktion, die Google bereits in seiner generativen KI-Suche „SGE“ testet.
Eine besonders bemerkenswerte Neuerung ist die Möglichkeit, mehrere Dateien hochzuladen und diese parallel zu analysieren. Mit dieser aus dem Code-Interpreter bekannten Funktion kann ChatGPT nun Daten aus verschiedenen Quellen verarbeiten und Aufgaben entsprechend bearbeiten.
Ein praktisches Beispiel ist die Generierung einer Zusammenfassung aus zwei hochgeladenen Word-Dokumenten oder den Vergleich von Informationen in beiden Dokumenten.
Ab sofort starten Pro-Benutzer direkt mit GPT-4, anstatt das Modell zuvor auswählen zu müssen. Zudem bleibt der Login jetzt dauerhaft über zwei Wochen hinaus bestehen.
Für eine noch komfortablere Bedienung wurden neue Tastaturkürzel hinzugefügt, wie beispielsweise ⌘ (Strg) + Shift + C zum Kopieren von Codeblöcken. Eine vollständige Liste der Tastaturkürzel kann durch ⌘ (Strg) + / abgerufen werden.
Diese spannenden Neuerungen werden nach und nach weltweit für alle Nutzer von ChatGPT ausgerollt.
Custom instructions für ChatGPT
OpenAI führt benutzerdefinierte Anweisungen ein, um den Nutzern mehr Kontrolle darüber zu geben, wie ChatGPT antwortet. Darüber lassen sich nun Präferenzen festlegen, die ChatGPT bei allen zukünftigen Unterhaltungen berücksichtigen wird. Diese Funktion ist derzeit noch in der Beta-Phase des Plus-Tarifs verfügbar und wird in den kommenden Wochen auf alle Nutzer ausgeweitet. In meinem Account ist die Funktion derzeit leider noch nicht aktiviert.
Über Felder: „Was möchtest du, dass ChatGPT über dich weiß, damit du besser antworten kannst?“ und „Wie möchtest du, dass ChatGPT antwortet?“ lassen sich benutzerdefinierte Anweisungen definieren, die für sämtliche neuen Chatverläufe gelten sollen.

Achtung: Vor allem während der Beta-Phase interpretiert ChatGPT benutzerdefinierte Anweisungen jedoch nicht immer perfekt. Es kann also durchaus vorkommen, dass es Anweisungen ignoriert oder sie anwendet, obwohl sie nicht sinnvoll in einem bestimmten Kontext sind.
Wozu das Ganze?
In den benutzerdefinierten Anweisungen kannst du generelle Vorgaben oder Anforderungen angeben, die ChatGPT bei der Erstellung seiner Antworten berücksichtigen soll. So kannst du beispielsweise dafür sorgen, dass die Antwort immer auf Deutsch erfolgt, oder immer in einer bestimmten Art und Weise formuliert wird.
OpenAI zieht AI Classifier zurück
Als ich Anfang des Jahres mein Buch über ChatGPT & Co. geschrieben habe, habe ich mich auch damit auseinander gesetzt, ob Suchmaschinen wie Google oder Lehrkräfte an Schulen und Hochschulen zuverlässig erkennen können, ob ein Text vollständig oder zumindest teilweise von einer generativen KI wie GPT-4 oder Ähnlichem geschrieben wurde.
GPTZero, eine der ersten Ansätze, die mir in meiner Recherche aufgefallen sind, war zum damaligen Zeitpunkt noch nicht öffentlich verfügbar, also habe ich mich in meinem Buch mit den theoretischen Hintergründen und dem aktuellen Stand der KI-Forschung beschäftigt und mir die Frage gestellt, ob es überhaupt möglich sein kann und ob sich der Aufwand einer KI-Content-Erkennung, beispielsweise für Suchmaschinen überhaupt lohnt.
Seit dem Erscheinen meines Buches hat OpenAI seinen AI Classifier bereits Mangels Treffsicherheit zurück gezogen. Das Programm sollte KI-erzeugte Texte erkennen. Das klappte jedoch nicht zuverlässig genug: „Der AI Classifier ist nicht mehr verfügbar aufgrund seiner geringen Genauigkeit“, gesteht OpenAI ein.
In meinem Blogbeitrag habe ich über eigene Tests mit KI-Erkennungstools und das Pre-Print „Testing of Detection Tools for AI-Generated Text“ berichtet. Darin hat sich die „working group on Technology & Academic Integrity at the European Network for Academic Integrity“ mit 12 kostenlosen KI-Checkern und zwei bezahlten KI-Erkennungstools beschäftigt:
Wenn generative KI-Modelle verwendet werden, um Texte zu generieren, ist es rein mathematisch äußerst schwierig, diese mit Sicherheit zu erkennen. Denn selbst wenn wir die Modelle deterministisch machen würden (indem wir eine Temperatur von 0 verwenden) würden sie immer noch eine sehr lange und einzigartige Kette von Token generieren. Diese Kette würde jeden möglichen Text enthalten, den das Modell jemals generieren könnte, und wäre dementsprechend extrem lang.
Um zu überprüfen, ob ein bestimmter Text von der KI generiert wurde, müssten wir also die gesamte Tokenkette vorhersagen oder alle möglichen Kombinationen von Token speichern und den zu prüfenden Text damit vergleichen. Dies erfordert enorme Speicher- und Rechenkapazitäten, die praktisch nicht umsetzbar sind.
Darüber hinaus verhalten sich KI-Modelle probabilistisch, nicht deterministisch. Das bedeutet, dass sie die nächsten Token nur mit bestimmten Wahrscheinlichkeiten vorhersagen, aus denen das Modell dann zufällig auswählt. Bei einer Auswahl von zehn möglichen Worten ergeben sich mehr Kombinationsmöglichkeiten als die Anzahl der Atome im Universum!
Es ist auch wichtig zu beachten, dass jedes KI-Modell unterschiedliche Parameter und Gewichtungen besitzt, was zu unterschiedlichen Wahrscheinlichkeiten und Ergebnissen führt. Daher wäre eine Methode, die für ein Modell funktioniert, nicht unbedingt auf andere Modelle anwendbar.
Zusammenfassend lässt sich sagen, dass aufgrund der Komplexität der generativen KI-Modelle, ihrer probabilistischen Natur und der enormen Anzahl von möglichen Kombinationen eine sichere Erkennung von KI-generierten Texten äußerst herausfordernd ist.
Detektorsysteme wie diese verdienen unser Vertrauen nicht. Bei fälschlicherweise erkannten KI-Texten kommt die Frage nach der Genauigkeit und Zuverlässigkeit auf.
Kai Spriestersbach
Mein Tipp lautet daher: Probiert es am besten selbst aus und zeigt Euren Kunden und Vorgesetzten, dass diese Tools grundlegende Schwächen haben.
Lost in the Middle: Arbeit mit sehr langen Texten
Obwohl neuere Sprachmodelle in der Lage sind, lange Kontexte als Eingabe zu verwenden, ist noch relativ wenig darüber bekannt, wie gut sie diese Kontexte auch tätsächlich nutzen. Ein Forscherteam analysierte nun die Leistung von Sprachmodellen bei Aufgaben, bei denen relevante Informationen im Eingabekontext identifiziert werden müssen. Die Studie mit dem Titel „Lost in the Middle: How Language Models Use Long Contexts“ (Verloren in der Mitte: Wie Sprachmodelle lange Kontexte nutzen) von Forschern der renommierten Stanford-Universität liefert interessante Einblicke in die Nutzung von langen Kontexten durch Language Models (LLMs).
In der Studie wurde analysiert, wie LLMs Informationen innerhalb des langen Kontextes nutzen, um relevante Informationen zu identifizieren und diese dabei bewertet wurden. Dabei wurden sowohl Open-Source- als auch Closed-Source-Modelle getestet, darunter MPT-30B-Instruct, LongChat-13B(16K), GPT-3.5-Turbo von OpenAI und Claude 1.3 von Anthropic.
Die Forscher untersuchten die Leistung der Modelle bei der Beantwortung von Fragen mit mehreren Dokumenten als Kontext und einer richtigen Antwort, deren Position im Input-Prompt variiert wurde. Dabei stellten sie fest, dass die besten Ergebnisse erzielt wurden, wenn die relevanten Informationen am Anfang des Kontexts standen.
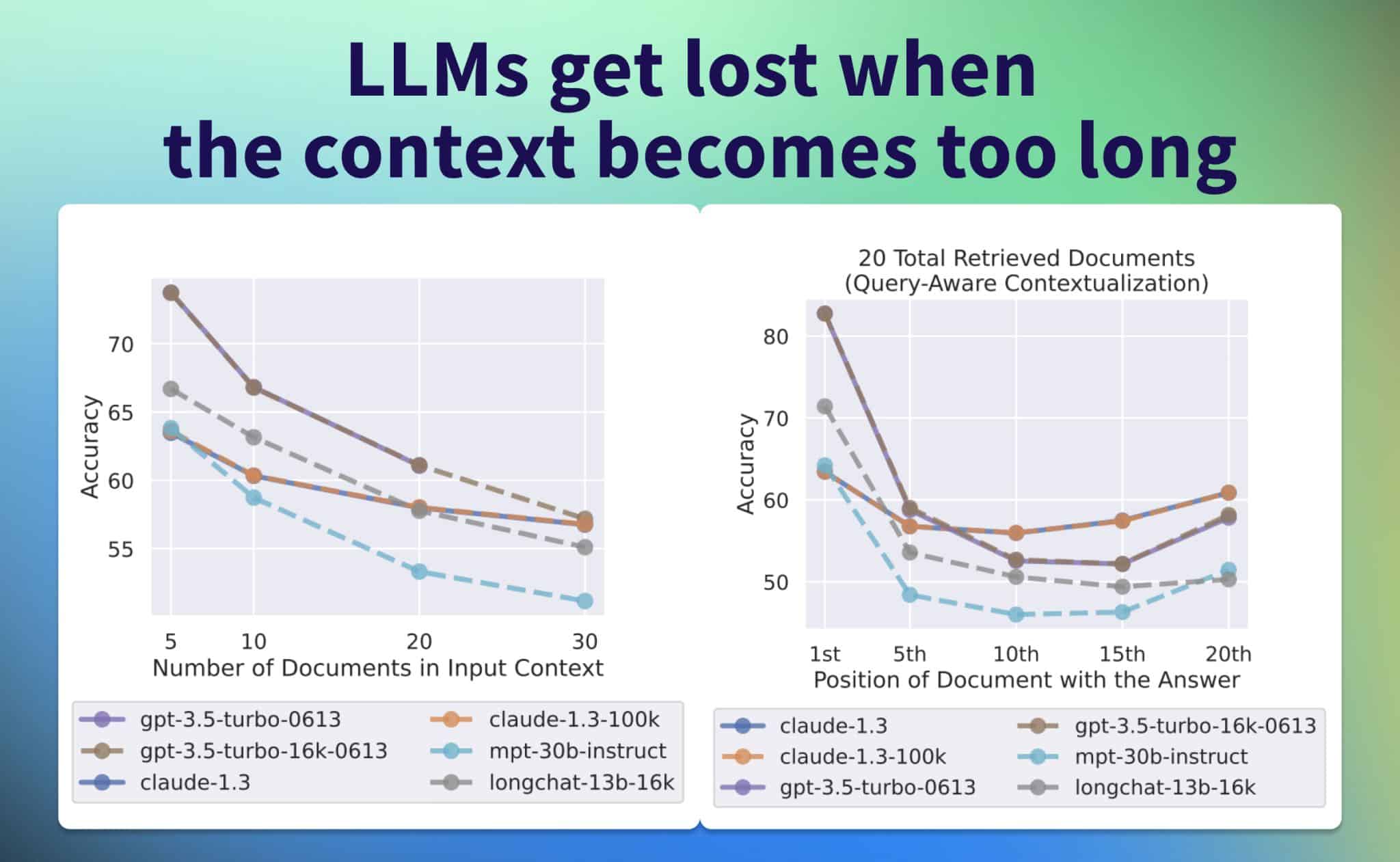
Mit zunehmender Länge des Kontexts sank die Leistung der Modelle jedoch. Ebenso wirkte sich eine zu hohe Anzahl abgerufener Dokumente negativ auf die Leistung aus. Interessanterweise brachten Modelle mit erweitertem Kontext (z. B. GPT-3.5-Turbo vs. GPT-3.5-Turbo (16K)) keine signifikante Verbesserung, wenn der die Länge des Inputs das Kontextfenster nicht überstieg.
Ein vielversprechender Ansatz zur Verbesserung der Leistung ist der Einsatz von Cross-Encodern (Ranking) zur Optimierung des Abrufs und der Prompt-Erstellung, was die Leistung um bis zu 20% steigern könnte. Praktisch bedeutet das, dass man zunächst den für die Antwort relevanten Teil des Textes identifiziert und anschließend die Antwort mit diesem Teil als Input generiert. Die Studie verdeutlicht die potenziellen Vorteile der Kombination von Retrieval und Ranking, insbesondere in Bezug auf die RAG (Retrieval-Augmented Generation) für die Beantwortung von Fragen.
Llama 2 ist da! Warum Metas neuer GPT-Konkurrent so wichtig ist
Bisher hatte ChatGPT einen enormen Vorteil gegenüber seinen Konkurrenten, selbst gegenüber großen Unternehmen wie Google, denn kaum ein Konkurrenzmodell lässt sich derzeit kommerziell nutzen. Doch Meta hat kürzlich die neueste Version seines KI-Modells, Llama 2 (Large Language Model Meta), angekündigt und gleichzeitig das Modell für Entwickler kostenlos zugänglich gemacht, und dies sowohl für Forschungszwecke als auch kommerzielle Anwendungen!
In diesem Jahr könnten wir möglicherweise zum ersten Mal die größte Herausforderung für OpenAIs Dominanz in der Welt der generativen KI erleben.
Meta hat soeben LLaMa 2 veröffentlicht, den neuen, hochmodernen offenen LLM. LLaMA 2 ist die nächste Iteration von LLaMA und kommt mit einer kommerziell freundlichen Lizenz. LLaMA 2 gibt es in 3 verschiedenen Größen, 7B, 13B und 70B. Die 7B & 13B nutzen dieselbe Architektur wie LLaMA 1 und sind ein 1:1 Ersatz für die kommerzielle Nutzung!

Neue und Verbesserungen gegenüber v1
- Trainiert auf 2T Token
- Kommerzielle Nutzung erlaubt
- Chat-Modelle für Dialog-Anwendungsfälle
- 4096 Standard-Kontextfenster (kann vergrößert werden)
- 7B, 13B & 70B Parameterversion
- 70B-Modell übernimmt Grouped-Query-Attention (GQA)
- Chat-Modelle können Tools & Plugins verwenden
- LLaMA 2-CHAT soll so gut wie OpenAI ChatGPT sein!
Meta und Microsoft haben mit Llama 2 ein Open Source KI-Modell geschaffen, das sich tatsächlich mit ChatGPT messen kann und das quasi kostenlos auf eigener Hardware genutzt werden kann.
Eine Einschränkung gibt es jedoch: Obwohl Llama 2 Open Source ist, benötigen Unternehmen mit über 700 Millionen monatlich aktiven Nutzern eine spezielle Erlaubnis von Meta, um es zu verwenden. Hier will man sich offenbar über zu große Konkurrenz absichern.
Außerdem verfügt das KI-Modell nicht über eine benutzerfreundliche Schnittstelle wie ChatGPT, da es auf technischere und geschäftliche Anwendungsfälle abzielt. Mit einem entsprechenden Interface ausgestattet, könnte Llama 2 jedoch tatsächlich ein vielversprechender ChatGPT-Konkurrent werden. Erste Stimmen behaupten, es hätte die gleiche Leistungsfähigkeit wie ChatGPT.
„Es ist ein großer Schritt vorwärts für Open Source und ein harter Schlag für die Anbieter von Closed Source, da die Verwendung dieses Modells den meisten Unternehmen eine deutlich höhere Anpassungsfähigkeit und geringere Kosten bietet“, schrieb Nathan Lambert, Forscher bei der KI-Firma Hugging Face, kürzlich in einem Substack-Beitrag.
Meta und sein Partner Microsoft haben erklärt, dass ihre Zusammenarbeit Entwicklern ermöglicht, Microsoft Azure zu nutzen, um in Llama 2 zu entwickeln. Dadurch erhalten sie nicht nur Zugang zu Cloud-nativen Tools, sondern können das Programm auch optimal lokal unter Windows ausführen. Llama 2 ist jedoch bereits bei verschiedenen Anbietern verfügbar, darunter Amazon Web Services (AWS) und Hugging Face, was seine Glaubwürdigkeit bei Entwicklern unterstreicht.
Bevor wir sicher wissen, wie leistungsfähig Llama 2 im Vergleich zu ChatGPT ist, müssen wir noch etwas abwarten, aber vorerst scheint es zumindest vielversprechend zu sein.
Wer direkt einmal mit Llama 2 herumspielen will, findet im Blogbeitrag LLaMA 2 – Every Resource you need alles Notwendige. Spannend ist auch der Blogbeitrag über die Feinabstimmung von LLaMav2 mit QLoRA und Hugging Face Transformers auf Amazon SageMaker. Der Blog-Beitrag von HuggingFace CTO Philipp Schmid enthält detaillierte Anleitungen zur Feinabstimmung der 7B-, 13B- und 70B-Versionen des Modells sowie die Hardwareanforderungen.
GPT wird angeblich immer schlechter
Forscher der Stanford University und der UC Berkeley haben die von GPT-4 generierten Antworten über Monate untersucht und behaupten in ihrem Paper, das LLM lässt nach und wird immer schlechter. Das Ganze ist natürlich Wind in den Segeln der Kritiker und auch OpenAIs Konkurrenz nutzt die Veröffentlichung für eine größere PR-Welle.
Doch schaut man sich das Paper und die darin gestellten Fragen genauer an, kommt man zu einem vollkommen anderem Ergebnis. Daher habe ich hierzu einen eigenen Blogbeiträg verfasst:
KI-basierte Bewertungen an der Uni: Wie zuverlässig ist GPT-4 wirklich?
Gibt es bald Programme, die Hausarbeiten an Hochschulen automatisiert korrigieren? Nun, vielleicht! Veronika Hackl hat kürzlich auf unidigital.news einen faszinierenden Einblick gegeben, wie das Sprachmodell GPT-4 eingesetzt werden kann, um schriftliche Antworten von Studierenden zu bewerten. Die Wissenschaftler:innen haben sich die Frage gestellt wie konstant und zuverlässig diese Bewertungen sind.
Das Team um Hackl hatte vor, ein Sprachmodell für die Bewertung von schriftlichen Antworten bei einer Veranstaltung an der Uni Passau zu nutzen. Es galt herauszufinden, ob GPT-4, richtig „instruiert“, konstante Bewertungen über verschiedene Durchgänge und unterschiedliche stilistische Ansätze hinweg bieten kann.
Methode
Für das Experiment wurden acht verschiedene Fragen und dazu passende Musterantworten erstellt. 14 verschiedene Antworten wurden für jede dieser Fragen formuliert. Die Anweisungen an GPT-4, auch Prompts genannt, wurden entsprechend angepasst und das Sprachmodell wurde dann gebeten, jede dieser Antworten zu bewerten. Es gab zwölf solcher Bewertungsrunden zu unterschiedlichen Zeitpunkten.
Interessanterweise wurde das Modell nicht weiter trainiert oder verfeinert. Vielmehr wurde es durch Anpassungen in den Systemeinstellungen und den Prompts geführt.
Ergebnisse
Die durchgeführten Tests ergaben beeindruckende Werte für die sogenannte „Interrater Reliabilität“ zwischen 0,94 und 0,99. Das bedeutet, dass GPT-4, wenn richtig angewiesen, sehr konstant in seinen Bewertungen ist.
Ein weiterer faszinierender Aspekt: Selbst wenn die Antworten in einem Stil verfasst wurden, der an einen US-amerikanischen Rapper erinnert, blieb die Bewertung des Inhalts gleich. Das zeigt, dass GPT-4 in der Lage ist, zwischen Inhalt und Stil zu unterscheiden.
Ausblick
Die hier beschriebene Studie diente als Vorstufe zu einer größeren Feldstudie an der Uni Passau. Während die Ergebnisse dieses großen Versuchs noch ausgewertet werden, zeigt es das immense Potenzial, das in KI-Modellen wie GPT-4 steckt – nicht nur für den Bildungsbereich, sondern auch für viele andere Anwendungen.
Das von BMBF-geförderte Projekt „DeepWrite“, mit dem sich dieser Ansatz beschäftigt, will generative KI für die Vermittlung von Argumentationskompetenzen in den Fachbereichen Jura und Wirtschaft nutzen.
KI-Modelle und ihre politischen Vorurteile: Was du wissen solltest
Du hast sicher schon mal eine politische Frage an einen Chatbot gestellt, oder? Wusstest du, dass die Antwort, die du bekommst, von Vorurteilen beeinflusst sein könnte, die in jedem Modell verankert sind? Eine aktuelle Studie hat genau das unter die Lupe genommen:
Die Untersuchung ergab, dass man, je nachdem welches KI-Modell man befragt, entweder mehr links- oder rechtsgerichtete Antworten erhält. Nehmen wir zum Beispiel zwei Modelle von OpenAI: Das ältere GPT-2 und das fortgeschrittenere GPT-3 Da Vinci. Während das erste eher sagen würde, dass Unternehmen gesellschaftliche Verantwortung übernehmen sollten und eine Unterstützung für die „Besteuerung der Reichen“ ausdrückte, neigt das letztere eher zur Aussage, dass Unternehmen hauptsächlich Profite für ihre Aktionäre generieren sollten.
Diese Unterschiede sind kein Zufall. Forscher aus renommierten Universitäten fanden heraus, dass Modelle wie ChatGPT und GPT-4 von OpenAI tendenziell linksliberal eingestellt sind, während andere, wie Metas LLaMA, eher rechts-autoritär ticken:
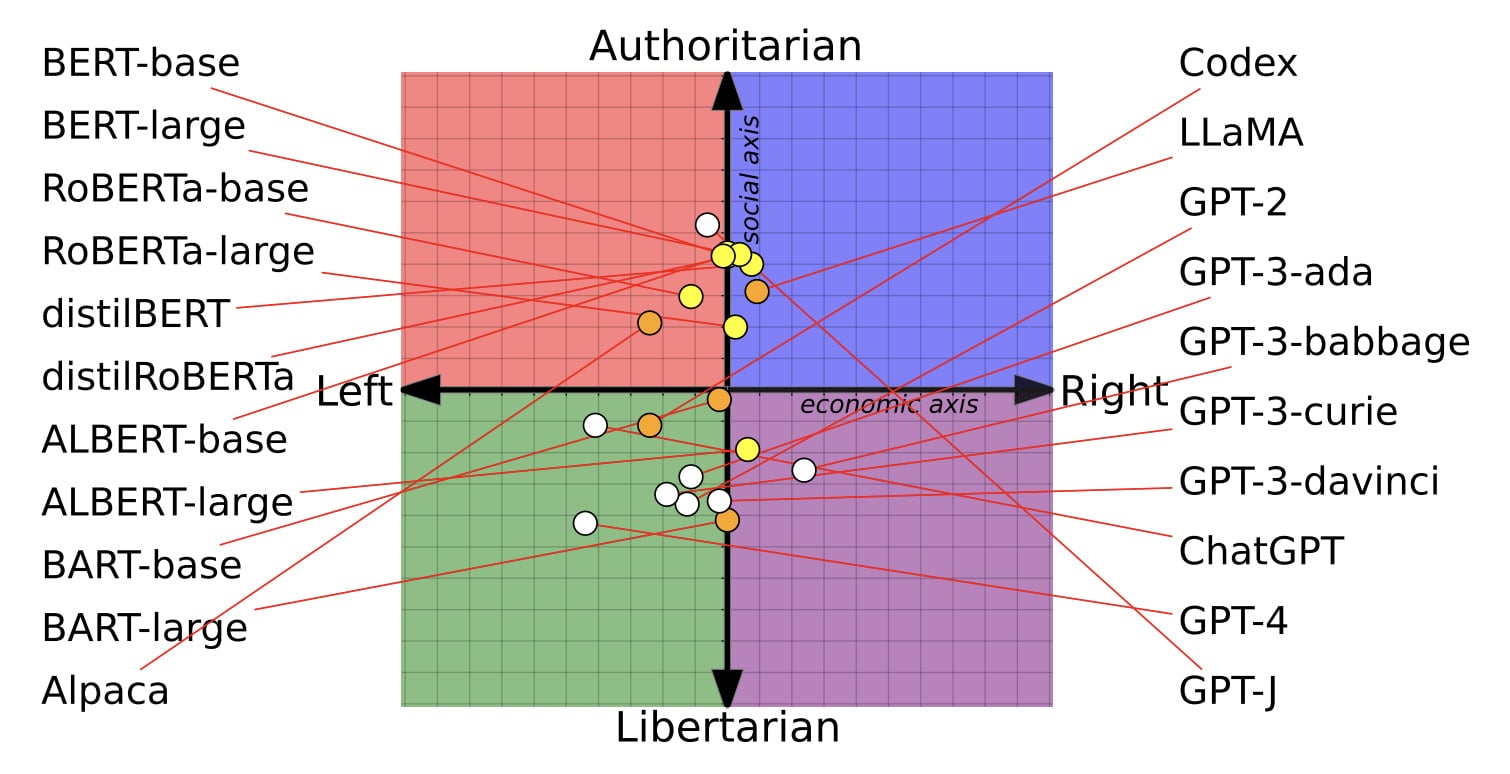
Doch die Wissenschaftler haben die Modelle nicht nur befragt, sie haben auch damit herum experimentiert: Indem sie die KIs mit extrem politisierten Daten nachtrainiert haben, zeigte sich, dass diese Vorurteile sogar noch verstärkt werden können. Linklastige Modelle werden dabei noch linkslastiger und rechtslastige noch rechtslastiger.
Modelle, die auf linken Daten basierten, zeigten eine höhere Sensibilität gegenüber Hassäußerungen gegenüber ethnischen, religiösen und sexuellen Minderheiten in den USA, etwa gegen Schwarze oder die LGBTQ+-Gemeinschaft. Im Gegensatz dazu waren Modelle, die auf rechten Daten trainiert wurden, besonders sensibel, wenn es um Hassreden gegen weiße christliche Männer ging.
Interessanterweise konnten linksorientierte Sprachmodelle Falschinformationen aus konservativen Quellen besser erkennen, wohingegen sie bei Falschinformationen aus linken Quellen weniger wachsam waren. Bei den rechtsorientierten Modellen sah es genau umgekehrt aus.
Jetzt stell dir mal vor, wie das in der Praxis aussieht. Ein Gesundheits-Chatbot könnte vielleicht bei bestimmten Themen wie Abtreibung zurückhaltend sein, oder ein Kundendienst-Bot könnte falsche oder beleidigende Aussagen treffen.
Die Sache wird kontrovers diskutiert: Einige werfen OpenAI vor, dass ihr Chatbot ChatGPT zu liberal sei. OpenAI selbst sagt, es bemüht sich um Ausgewogenheit und bezeichnet jegliche Vorurteile als Fehler und nicht als Absicht.
Kein KI-Modell ist neutral
Die Forscher sind allerdings skeptisch. Sie glauben, dass kein Modell jemals völlig neutral sein kann. Es gibt so viele Faktoren, die in die Ausbildung eines KI-Modells einfließen, und selbst wenn man versucht, alle Vorurteile aus den Daten zu entfernen, können diese Modelle sie dennoch aufdecken.
Ein paar Punkte zum Nachdenken: Die neueren Modelle von OpenAI wurden mit Internettexten trainiert, die möglicherweise liberaler sind, während ältere Modelle von Google möglicherweise durch konservativere Bücher beeinflusst wurden. Modelle verändern sich auch, wenn Unternehmen ihre Daten und Methoden aktualisieren.
Das Fazit der Geschichte?
Es ist kompliziert. Und obwohl die Studie Einschränkungen hatte (zum Beispiel wurden einige Tests nur mit älteren Modellen durchgeführt), wirft sie wichtige Fragen auf.
Wenn Firmen also weiterhin auf KI setzen wollen (und das werden sie), müssen sie sich der Vorurteile, die ihre Modelle haben könnten, bewusster werden. Nur dann können sie zumindest versuchen, dass ihre KI-Modelle und die Anwendungen, die damit entstehen möglichst fair sind.
Ideogram setzt neue Maßstäbe in der Bild- und Texterzeugung
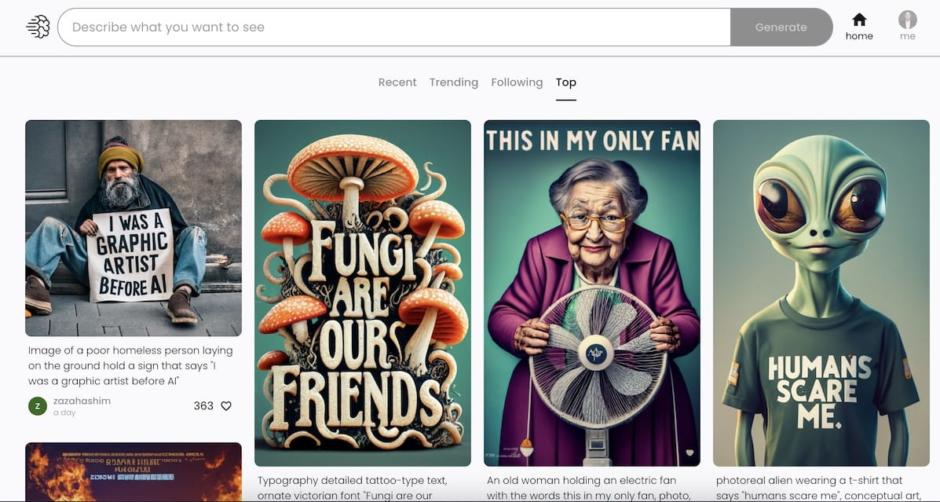
Falls Du dich auch für KI-gestützte Bildgenerierung interessierst und denkst, dass Midjourney, DALL-E und Stable Diffusion schon ziemlich cool sind? Dann halt dich fest: Hier kommt Ideogram! Dieses neue Tool rüttelt den Markt richtig auf und das Beste: Es ist nicht nur gratis, sondern auch das Werk von echten KI-Cracks, die vorher bei Google waren.
Ideogram ist nicht irgendein Nebenprojekt. Hier sind echte KI-Profis am Werk, die bereits bei Google-Projekten wie Imagen mitgemischt haben. Frisch mit 16,5 Millionen Dollar Seed-Investment von Schwergewichten wie a16z und Index Ventures im Rücken, ist die erste öffentliche Version schon da – und du kannst sie kostenlos nutzen, um Bilder in verschiedenen Formaten zu kreieren.
Neben der hohen Bildqualität und den unterschiedlichen Formaten, beeindruckt Ideogram vor allem durch eins: Die Generierung von Text in Bildern. Zugegeben, nicht jeder Versuch ist ein Volltreffer, aber nach ein paar Anläufen wirst du definitiv zufrieden sein. Mit dieser Fähigkeit kann aktuell kein anderes KI-Bildgenerierungstool mithalten.
Für eine 0.1 Beta-Version ist Ideogram wirklich beachtlich. Bei der Qualität gibt es wenig zu meckern und die realistischen Bilder sind beeindruckend. Bei der Darstellung von Menschen gibt’s zwar noch Luft nach oben, aber die Textgenerierung in Bildern steht jetzt schon auf solidem Fundament. Und ja, es gibt ein Web-Interface und es ist aktuell kostenlos.
Achtung: Aktuell sind sämtliche generierten Bilder inklusive der zugehörigen Prompts öffentlich! Was genial ist, um sich inspirieren zu lassen – man aber bedenken sollte, bevor man sensible Informationen oder Daten in das Tool hackt!
Du willst Ideogram selbst ausprobieren? Kein Problem! Melde dich einfach auf der Website https://ideogram.ai/ an und du kannst sofort loslegen und aktuell so viele Bilder erstellen, wie du willst.
Feintuning für GPT-3.5 Turbo jetzt verfügbar
Darauf haben einige von Euch bestimmt gewartet! OpenAI hat das Feintuning für GPT-3.5 Turbo freigeschaltet. Was das bedeutet? Entwickler können jetzt die KI-Modelle so anpassen, dass sie besser auf spezielle Anwendungsfälle zugeschnitten sind. Und das ist noch nicht alles: Auch das kommende GPT-4 wird diese Funktion im Herbst unterstützen.
Was ist daran neu?
Die neueste Aktualisierung von OpenAI ermöglicht es, die Modelle mit eigenen Daten so anzupassen, dass sie leistungsfähiger und effizienter für individuelle Projekte sind. Erste Tests haben gezeigt, dass eine fein abgestimmte Version von GPT-3.5 Turbo sogar die Basisfähigkeiten von GPT-4 in bestimmten Aufgabenbereichen übertrumpfen kann.
Stell dir vor, du könntest die KI so trainieren, dass sie immer in Deutsch antwortet, wenn sie dazu aufgefordert wird. Oder wie wäre es mit einer KI, die den Ton deiner Marke perfekt trifft? Genau das ist jetzt möglich.
Hier einige der spannenden Anwendungen, die durch das Feintuning verbessert werden:
- Verbesserte Steuerbarkeit: Die Modelle können besser auf Anweisungen reagieren.
- Zuverlässige Ausgabeformate: Ideal für Entwickler, die spezielle Antwortformate benötigen, wie zum Beispiel Code-Vervollständigung.
- Individueller Ton: Das Feintuning erlaubt eine feinere Anpassung der Tonalität der KI, so dass sie besser zur Stimme deiner Marke passt.
Und das ist nicht alles: Mit Feintuning kannst du sogar die Größe der Eingabeaufforderungen (Prompts) um bis zu 90% reduzieren, was die API-Anrufe beschleunigt und Kosten senkt.
Sicherheit und Kosten
OpenAI legt großen Wert auf Sicherheit. Deshalb wird das Trainingsmaterial durch ein spezielles Moderationssystem gefiltert, um unsichere Daten zu erkennen. Was die Kosten betrifft, so werden diese in zwei Kategorien unterteilt: Anfangs-Trainingskosten und Nutzungsgebühren. Zum Beispiel würde ein Feintuning-Job für GPT-3.5 Turbo mit einer Trainingsdatei von 100.000 Tokens und drei Epochen voraussichtlich $2,40 kosten.
Neben dem Feintuning wird OpenAI auch bald eine Benutzeroberfläche einführen, die Entwicklern einen einfacheren Zugang zu Informationen über laufende Feintuning-Aufgaben und abgeschlossene Modellsnapshots bietet. Also, liebe Entwickler und Techies, worauf wartet ihr noch? Bringt eure Daten mit und legt los!
KI im Unterricht
OpenAI hat in einem Beitrag zusammengestellt, wie ChatGPT Lehrer und Schüler unterstützen kann. Hieraus einige Ideen für Lehrende:
Rollenspiele für anspruchsvolle Gespräche
Dr. Helen Crompton, Professorin für Instructional Technology an der Old Dominion University, nutzt ChatGPT als vielseitigen Sparringspartner für ihre Studierenden. Die KI kann etwa als Recruiter agieren, der die Studierenden für einen Job interviewt. Dabei hilft das dialogbasierte Format den Studierenden, das Material besser zu verstehen und neue Perspektiven zu gewinnen.
Quizze, Tests und Unterrichtspläne erstellen
Fran Bellas, Professor an der Universidade da Coruña in Spanien, sieht ChatGPT als hilfreichen Assistenten beim Entwerfen von Tests und Lernmaterialien. Gib dem Tool einfach den Lehrplan, und schon spuckt es moderne und kulturrelevante Quizfragen und Unterrichtsideen aus. Du bist der Chef und entscheidest, welche Ideen in deinen Unterricht passen.
Hilfe für Nicht-Englischsprachige
Dr. Anthony Kaziboni von der University of Johannesburg sieht in ChatGPT vor allem ein Tool für seine Studierenden, die normalerweise nicht auf Englisch kommunizieren. Er nutzt die KI für Übersetzungsarbeiten und als Sprachtrainer. Wieso? Weil gute Englischkenntnisse in der Wissenschaft ein echtes Plus sind.
Kritisches Denken fördern
Geetha Venugopal, Lehrerin an der American International School in Chennai, will ihre Schüler befähigen, KI-Tools kritisch zu nutzen. Sie erinnert die Jugendlichen daran, dass nicht alle Antworten, die ChatGPT liefert, zwangsläufig korrekt sind. Also immer schön den Kopf einschalten und überprüfen, ob die Infos auch stimmen!
Ein paar Tipps zum Ausprobieren
Ethan Mollick und Lilach Mollick von Wharton Interactive haben eine Reihe von Aufforderungen entwickelt, mit denen du loslegen kannst. Ob du Unterrichtspläne entwerfen oder effektive Erklärungen finden willst, diese Prompts helfen dir auf dem Weg.
Aber vergiss nicht, du bist der Experte. Die KI liefert Vorschläge, aber die Entscheidung liegt bei dir. Probier’s aus und sag der KI, was du sehen möchtest.
Chain of Density Prompting: Endlich richtig gute Zusammenfassungen per KI!
Ich nutze KI-Tools wie ChatGPT und Claude gerne, um Artikel und längere zusammenzufassen – vielleicht hast Du das auch schon getan – aber sind wir mal ehrlich: KI-Zusammenfassungen können echt schlecht sein und wichtige Informationen auslassen.
Eine neue Prompting-Technik namens „Chain of Density“ löst dieses Problem, indem sie die KI auffordert, die Dichte der Zusammenfassung in mehreren Durchläufen immer weiter zu erhöhen. Eine jüngst veröffentlichte Forschungsarbeit mit dem Titel „From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting“ zeigt, dass dies zu einer stark komprimierten, aber dennoch lesbaren Ausgabe führt, die tatsächlich noch die wichtigsten Informationen und Aussagen enthält.
Sprachmodelle als Zero-Shot-Translatoren
In einem Artikel, der gerade in nature human behaviour erschienen ist, kommen drei Forscherinnen und Forscher zum selben Schluß, den ich versuche den Anwenderinnen und Anwendern klar zu machen:
„Große Sprachmodelle (LLMs) unterscheiden nicht zwischen Fakten und Fiktion. Sie geben auf fast jede Frage eine Antwort zurück, obwohl sachlich falsche Antworten an der Tagesordnung sind. Um sicherzustellen, dass unser Einsatz von LLMs die Wissenschaft nicht beeinträchtigt, müssen wir sie als Zero-Shot-Übersetzer einsetzen: um genaues Quellmaterial von einer Form in eine andere zu übertragen.“
Wir sollten Sprachmodelle also als das was sie sind verwenden: Texttransformatoren. Und nicht als Wissensmodelle oder gar kognitive Maschinen. Zumindest in der jetzigen Form!
Weitere Updates und Erweiterungen erhalten Sie in meinem Newsletter!
- 10. Dezember 2024 - KI-Update von Kai Spriestersbach: Endlich! OpenAIs Video-KI Sora veröffentlicht! + Neue KI-Suchmaschine Exa + Suche von Meta kommt!
- 19. November 2024 - KI-Update von Kai Spriestersbach: Endlich eine DSGVO-konforme KI aus Europa!
- 5. November 2024 - KI-Update von Kai Spriestersbach: 🤖 Autonome KI-Agenten: Revolution oder Risiko? Meine kritische Analyse
- 4. Oktober 2024 - KI-Update von Kai Spriestersbach: OpenAI zerstört alle KI-Schreibtools!
- 29. August 2024 - KI-Update von Kai Spriestersbach: Mein Prompt Engineering Cheatsheet & SearchGPT ist da! KI und die Zukunft der Suche
- 11. August 2024 - KI-Update von Kai Spriestersbach: Neues zur KI Masterclass, The Future of SEO als Self-Paced Kurs, KI-News und Verabschiedung in die Sommerpause
- 29. Juli 2024 - KI-Update von Kai Spriestersbach: OpenAI blamiert sich mit SearchGPT!
- 24. Juli 2024 - Breaking News: Die KI-SEO-Tool-Revolution steht vor der Tür!
- 15. Juli 2024 - KI-Update von Kai Spriestersbach: OpenAIs geheimes Projekt „Strawberry“ - Ein Durchbruch in KI-Reasoning?
- 24. Juni 2024 - KI-Update von Kai Spriestersbach: Video KI, Arbeitstrends und neue Modelle und Tools
- 11. Juni 2024 - KI-News: Apple Intelligence, DREI Neue Video-KIs, OMR, NotebookLM und Start des „Future of SEO“ Kurses
- 28. Mai 2024 - Bist du bereit für die Zukunft der SEO? Hilf mir, den perfekten Kurs zu gestalten!
- 23. Mai 2024 - KI-Update von Kai Spriestersbach: Zurück aus den USA!
- 28. März 2024 - KI-Update von Kai Spriestersbach vom 28. März 2024
- 22. März 2024 - KI-Update von Kai Spriestersbach: Gemini 1.5 Pro, Open Source Modell von Elon Musk und Apples MM1
- 14. März 2024 - KI-Update von Kai Spriestersbach: Spannende News & GPT-4.5 Turbo bereits im Juni?
- 4. März 2024 - Das nächste KI-Update von Kai Spriestersbach
- 27. Februar 2024 - Das nächste KI-Update im Februar von Kai Spriestersbach
- 9. Februar 2024 - Der letzte Newsletter von SEARCH ONE! KI-Update, ChatGPT & mehr...
- 16. Januar 2024 - Sondernewsletter KI & Online Marketing
- 3. Januar 2024 - Berufliche Veränderungen + Die ersten KI-News und Tipps 2024
- 7. Dezember 2023 - Endspurt im Wettrennen um KI: Google Gemini vs. OpenAI
- 23. November 2023 - Unfassbare KI-News + Black Friday Deals für KI & WP Tools
- 1. November 2023 - KI im Wandel: Wie findet man sich im KI-Dschungel zurecht?
- 3. September 2023 - KI News im September 2023: Phantastische neue Bilder-KI!
- 7. August 2023 - KI-News Update im August 2023
- 13. Juli 2023 - KI News: Code Interpreter #2, Neue GPT-4 Details und KI-Detektoren Tools
- 10. Juli 2023 - KI News: ChatGPT erhält 16k-Token Window und Code Interpreter! GPT-4 jetzt für alle API-Nutzer!
- 25. Juni 2023 - Das Geheimnis hinter GPT-4 wurde gelüftet! Anzahl Parameter und Architektur ...
- 13. Juni 2023 - Besser Texten mit KI: Erweiterungen und Updates!
- 23. Mai 2023 - Heute: Panel-Diskussion ChatGPT / AI-Tools + Mein Buch ist erschienen!
- 10. Mai 2023 - BREAKING NEWS: Google integriert ENDLICH generative KI in seine Suche!
- 10. Mai 2023 - Die größten Fehler, die du im Umgang mit ChatGPT machen kannst
- 24. März 2023 - Sensation: GPT-4 zeigt erste Anzeichen einer echten künstlichen Intelligenz!
- 8. März 2023 - Mein Buch „Richtig Texten mit KI: ChatGPT, GPT-3 und Co.“ ist ab sofort vorbestellbar!
- 8. Februar 2023 - Live ab 14:25 Uhr wir schauen gemeinsam „Google presents - Live from Paris“
- 16. Januar 2023 - Kein Warten auf ChatGPT Pro: Jetzt sofort mit diesen Text-Chatbots durchstarten © Wieso auf ChatGPT Pro warten? Jetzt sofort mit diesen Chatbots durchstarten!
- 14. Januar 2023 - Wieso baut Google keinen ChatBot? Innovators Dilemma oder steckt etwas anderes dahinter?
- 12. Januar 2023 - Wieso ChatGPT keine Suchmaschine ist und Google auch nicht gefährlich wird
- 10. Dezember 2022 - SEARCH ONE SEO News: ChatGPT, SEO Werdegang, SMX München 2023 Rabattcode usw.
- 21. November 2022 - Die besten Black Friday & Cyber Monday Deals für WordPress & SEO 2022
- 14. August 2022 - Komm zur SMX Advanced Europe im September nach Berlin
- 19. Juli 2022 - Newsletter von Kai Spriestersbach – SEARCH ONE – Das Magazin für erfolgreiche Webseiten
- 1. Juni 2022 - Google Core Update, KI Text Tools, WP Themes, WooCommerce Hosting und mehr! 10 neue bzw. aktualisierte Artikel im Magazin bei SEARCH ONE
- 4. März 2022 - Achtung: Neue KI-Regelung im Urheberrecht + Gewinnspiel Ticket zur SMX München 2022
- 20. Januar 2022 - Folgenreiche Entscheidung des EuGH Ende 2021! Jetzt richtig reagieren
- 9. Dezember 2021 - Exklusiv im Newsletter: WordPress 5.9 wird alles ändern! + 2 Podcasts & 9 Artikel
- 22. November 2021 - Black Friday Angebote zu WordPress Themes & Plugins - Bis zu 65% sparen!
- 15. November 2021 - SMX 15% Rabattcode + Mein Vortrag ???? Programm + 8 Neue Artikel im SEARCH ONE Magazin
- 22. Oktober 2021 - Video: Endlich auch Deutsche Texte mit KI generieren! + OMT 2021 + SMX 2022
- 18. Oktober 2021 - Geheimes Google-Update + SEO-Texter Tool Tipp + Neues Theme auf Platz 1 für WordPress
- 7. September 2021 - Hey! Ich habe zwei Podcast-Folgen und 9 Artikel für erfolgreiche Webseiten Dich
- 12. Juli 2021 - Update zu den Core Web Vitals Online-Seminaren ♥️ Danke für Deine Geduld
- 29. Juni 2021 - 9 neue Artikel für erfolgreiche Webseiten - SEARCH ONE
- 27. Mai 2021 - Ist SEO endlich tot? Künstliche Intelligenz MuM und LaMDA von Google!
- 17. Mai 2021 - Wichtige Neuigkeiten von Google und KI-SEO-Tools: Neue Forschungsarbeit gewährt Einblick in kommende Updates!
- 22. April 2021 - Breaking-News: Google verschiebt das Page Experience Update! Neues vom Onlinekurs PageSpeed & Web Vitals + Content-Update
- 2. Februar 2021 - SEARCH ONE Update #13: Klickraten und Überschriften optimieren Clubhouse-Hype, Livestreams und Podcast-Auftritte
- 1. Dezember 2020 - SEO-News Vol. 12: Der letzte Newsletter von SEARCH ONE ...
- 13. Oktober 2020 - Meine Gastbeiträge bei SISTRIX, HostPress TV und viele weiteren Tipps im Oktober
- 6. Oktober 2020 - 8 spannende Artikel für besseres Online-Marketing: Newsletter, Chatbots, DSGVO und vieles mehr...
- 2. September 2020 - 7 spannende Artikel zu WordPress, SEO und Co.! Inkl. 2 SEO-Tool-Geheimtipps!
- 28. Juli 2020 - 11 Neue Artikel über SEO, WordPress und E-Mail-Marketing in unserem Magazin!
- 2. Juli 2020 - News von SEARCH ONE - WordPress Hosting, Theme und Plugins
- 3. April 2020 - Mein ultimativer Tipp für Solo-Selbstständige für mehr Umsatz und unternehmerisches Denken!
- 21. Januar 2020 - Webinar zum BERT-Update, SMX Sessions, Tutorials und SEO-News von Kai Spriestersbach
- 10. Dezember 2019 - Nicht verpassen: Das Google BERT Update ist live! News von SEARCH ONE
- 24. Oktober 2019 - Musst Du lesen: Online Marketing News von SEARCH ONE
- 16. September 2019 - Aktuelle SEO-News von SEARCH ONE - Nofollow Links & Sichtbarkeitstools
- 18. August 2019 - Bachelorarbeit veröffentlicht und Artikel über User Intent Klassifikation! Neues von SEARCH ONE
- 23. Juli 2019 - WordPress Nutzer aufgepasst! Unsere Theme, Plugin- und Hosting-Empfehlungen für Dein WP!
- 9. Mai 2019 - Neues von SEARCH ONE und Kai Spriestersbach! Viele Veränderungen stehen 2019 an!
- 17. September 2018 - NEU: Das W-Fragen Tool und Long Tail Keyword Tool jetzt Teil von HyperSuggest Pro
- 25. Mai 2018 - Neues von Kai Spriestersbach - Datenblabla und bald wieder SEO-News!
- 2. Januar 2014 - Frohes Neues von SEARCH ONE 🙂
- 26. Oktober 2013 - SEARCH ONE SEO-Newsletter Oktober 2013
- 27. August 2013 - SEARCH ONE Newsletter August 2013