Alle reden über BERT. Google sagt, es handelt sich dabei um das größte Update seit fünf Jahren und um einen der größten Fortschritte im Bereich der Suchmaschinentechnologie überhaupt. Nun steht BERT auch bei uns vor der Tür. Doch was muss man dazu eigentlich wissen?

Um sich dieser Frage zu nähern, muss man sich in den Bereich der Computerlinguistik, auf Englisch Natural Language Processing (NLP), begeben: Bei BERT handelt es sich nämlich um ein sogenanntes künstliches neuronales Netz. Dieses besteht im Falle von BERT aus 120 bis 350 Millionen Neuronen. Das Besondere daran: Diese Netze trainiert man so lange, bis sie tun, was man will. Nur weiß man dann nicht so genau, wieso. Daher gibt es auch die Wissenschaft der BERTologie, auf Englisch BERTology, bei der man das Innere dieses Netzes untersucht, um herauszufinden, welche Gewichtungen zu den gewünschten Ergebnissen führen. Da mich das an eology erinnerte, habe ich meine diesjährige Präsentation für die SEOkomm in Salzburg so genannt. Übrigens haben weder ich selbst noch mein Vortrag noch die eology GmbH irgendetwas mit der Sekte Scientology zu tun!
1. BERT ist ein Google-Update
Nun ist BERT aber auch der Name des neuesten Updates von Google. Und jedes Mal, wenn eines der Google-Updates einen Namen bekommt, ist die Aufregung in der SEO-Szene besonders groß. Doch diesmal hat eigentlich niemand wirklich etwas gemerkt. Keine Listen von Gewinnern und Verlierern, keine Analysen, was sich geändert hat, keine Hinweise auf irgendetwas. Googles offiziellen Aussagen zufolge wirkt sich BERT auf etwa 10 % der englischsprachigen Suchanfragen aus. Für die Generierung der sogenannten Featured Snippets wird es, laut Google, hingegen bereits weltweit in allen Sprachen eingesetzt.
Viel mehr als ein paar Beispiele und allgemeine Erklärungen gibt es seitens Google nicht zum Update, daher schauen wir uns besser die Technik dahinter an. BERT ist ein technisch wegweisendes Modell zur Verarbeitung natürlicher Sprache, stammt aus Googles AI-Team und wurde im Jahr 2018 bereits in einem Forschungspapier veröffentlicht.
2. BERT ist ein NLP-Algorithmus
Seitdem hat der Algorithmus die NLP-Welt im Sturm erobert. So führt beispielsweise BERT in der Variante Albert das Squad 2.0 Leaderboard an, in dem Machine-Learning-Algorithmen daran gemessen werden, wie gut sie die Antworten auf Fragestellungen aus Texten geben können. Dabei werden die Netze zunächst mit einer Liste von Texten, Fragen und den richtigen Antworten trainiert und können später dann neue Texte verarbeiten und für neue Fragen die richtige Antwort finden.
Eine Besonderheit von BERT ist es, dass für die Beantwortung komplizierter Fragestellungen in speziellen Sachverhalten nicht wie bisher sehr große Datenmengen zum Training benötigt werden. Denn BERT wurde bereits auf Basis der englischen Wikipedia und des bookCorpus mit über 3 Milliarden Wörtern trainiert. Das ermöglicht es, mit relativ wenig Text für Nischen ein Spezialwissen aufzubauen und sehr hilfreiche Antworten geben zu können.
Eine weitere Besonderheit von BERT ist, dass man nicht mehr wie bisher für jede Aufgabe im NLP einen eigenen Algorithmus benötigt, beispielsweise um Fragen zu beantworten, Texte zu klassifizieren, für die Analyse des sog. Sentiments, also der Stimmung des Textes hinsichtlich bestimmter Entitäten und so weiter.
Wie Ludwig Wittgenstein, einer der bedeutendsten Philosophen des 20. Jahrhunderts, bereits in seinem im Jahre 1953 veröffentlichten Buch festgestellt hat, liegt die Bedeutung eines Wortes in seinem Gebrauch in der Sprache. Gerade für Computer sind Wörter erst mal nur eine scheinbar zufällige Aneinanderreihung von Buchstaben. Erst die Verwendung in Sätzen verleiht diesen Buchstabenhaufen einen Sinn. Doch gerade hier haben bisherige NLP-Systeme ihre Schwächen.
Beispielsweise bei den sogenannten Koreferenzen (auch Referenzidentität): Bei der Übersetzung des englischen Satzes “The animal didn’t cross the street because it was too tired.” bezieht sich das Wörtchen “it” für Menschen klar erkennbar auf “das Tier”, das die Straße nicht überquerte, da es zu müde war. Folglich lautet die korrekte Übersetzung für das Wort “it” eben “es” für “das Tier”. In dem fast identischen Satz “The animal didn’t cross the street because it was too wide.” hingegen bezieht sich “it” auf “die Straße” und so muss folglich in der Übersetzung “it” nicht mit “es”, sondern mit “sie” für “die Straße” übersetzt werden.

Für uns Menschen, die Sprache in jahrelangem Training gelernt haben, ist das vollkommen offensichtlich. Für einen Algorithmus ist die Auflösung dieser Koreferenzen jedoch alles andere als trivial und führte 2017 das Google-Team bei der Weiterentwicklung von Google Translate auf die Technologie der sogenannten Transformers. (Das T in BERT!)
Mit sogenannten Transformers lernt BERT die Wahrscheinlichkeit, dass “it” im ersten Satz für das Tier steht und dass “it” im zweiten Satz für die Straße steht. Hierbei muss jedoch der gesamte Satz berücksichtigt werden.

Eine weitere Herausforderung, die sich nur durch die Berücksichtigung des Kontexts lösen lässt, sind die sogenannten Homographe. Das Wort “Bank” kann sich zum einen auf ein Geldinstitut beziehen und zum anderen auf eine Sitzgelegenheit in einem Park. Betrachtet man nun noch Sprachassistenten und die sogenannte “Voice Search”, kommen auch noch die Homophone dazu, also Wörter, die zwar gleich klingen, aber anders geschrieben werden und natürlich mit einem anderen Sinn verbunden sind.
Wenn ich sage, ich möchte jetzt [ˈmaːlən], kann ich die kreative Tätigkeit meinen oder das Zerkleinern von Kaffeebohnen. Erst aus dem Kontext erschließt sich, was ich meine!

Klassische Word-Embeddings, wie word2vec, die man aus RankBrain kennt, können eine Menge cooles Zeug – aber nicht alles, denn sie sind kontextfrei! Sie würden also versuchen, beide Varianten von Bank im hochdimensionalen Raum auf denselben Punkt abzubilden. Theoretisch kann es “Bank” also nur einmal geben.
Besser machen dies autoregressive Modelle. XLnet, GPT oder GPT-2 sind Beispiele für diese Art von Algorithmen, die sich jedes Wort im Zusammenhang mit den Wörtern davor ansehen und so lernen, das jeweils nächste Wort vorherzusagen. Sie eignen sich besonders gut zur Textgenerierung.

Für ein optimales Verständnis ist aber auch eben das „danach“ eines Wortes sehr wichtig!
BERT schaut nun erstmals in beide Richtungen, denn das B in BERT steht für bidirectional/bidirektional. Beim Training wird jeweils ein Wort zufällig im Satz maskiert und so lernt BERT, fehlende Wörter vorherzusagen, ganz egal, wo sie stehen. Es betrachtet also den gesamten Kontext und nicht nur die Wörter davor oder dahinter.

Das Besondere am Training von BERT ist außerdem, dass immer zwei Sätze gleichzeitig gelernt werden. So kann auch der Kontext über Satzgrenzen hinweg berücksichtigt werden. Hierbei lernt BERT quasi den nächsten Satz vorherzusagen.

Doch was macht Google nun mit BERT?
Ein Jahr nach der Veröffentlichung von BERT als Forschungsarbeit gibt Google nun das algorithmische BERT-Update für seine Suche frei und betont seine Bedeutung für das Verständnis von Inhalten und Suchanfragen. NLP ist eben längst kein gelöstes Problem.
Auch googeln musste erstmal gelernt werden. Gerade in den Anfangszeiten der Web-Suchmaschinen mussten wir Menschen uns auf die Funktionsweise der suchwortorientierten Abfrage erst einmal einlassen. Meiner Mutter musste ich damals auch erst beibringen, wie man „richtig googelt“. Selbst bei der Voice-Search ist es momentan häufig noch so, dass wir die Sprache nur als Ersatz für die Tastatur benutzen, aber keine richtigen Dialoge mit der Maschine führen. Aber in Zukunft werden wir sehr wohl echte Gespräche mit unseren Geräten führen können. Wer sich das noch nicht so recht vorstellen kann, sollte sich einfach mal den Film „Her“ von Spike Jonze anschauen.
Beispiele: Suchanfragen mit und ohne BERT
Schaut man sich nun ein paar Beispiele aus dem Blogartikel von Google zur Veröffentlichung des BERT-Updates an, sieht man sehr schön, dass insbesondere bei „Conversational Searches“, also Suchen in natürlicher Sprache, der „Intent“, also die tatsächliche Absicht des Suchenden, besser verstanden werden kann.
Nehmen wir zum Beispiel die Suchanfrage “2019 brazil traveler to usa need a visa”. Als Google-Ergebnis wurde vor BERT eine Seite ganz oben gerankt, in der erklärt wurde, dass Staatsbürger der Vereinigten Staaten nach Brasilien ohne Visa einreisen können. Das Wörtchen “to” wurde also ignoriert, obwohl es doch gerade in dieser Suchanfrage den besonderen Kniff darstellt. Jetzt mit BERT kommt die korrekte Seite ganz oben, auf der man sich als Brasilianer ein Visum für die USA besorgen kann. Ähnliche Beispiele gab es damals bereits bei Hummingbird und RankBrain, funktional ist BERT also eine Weiterentwicklung.
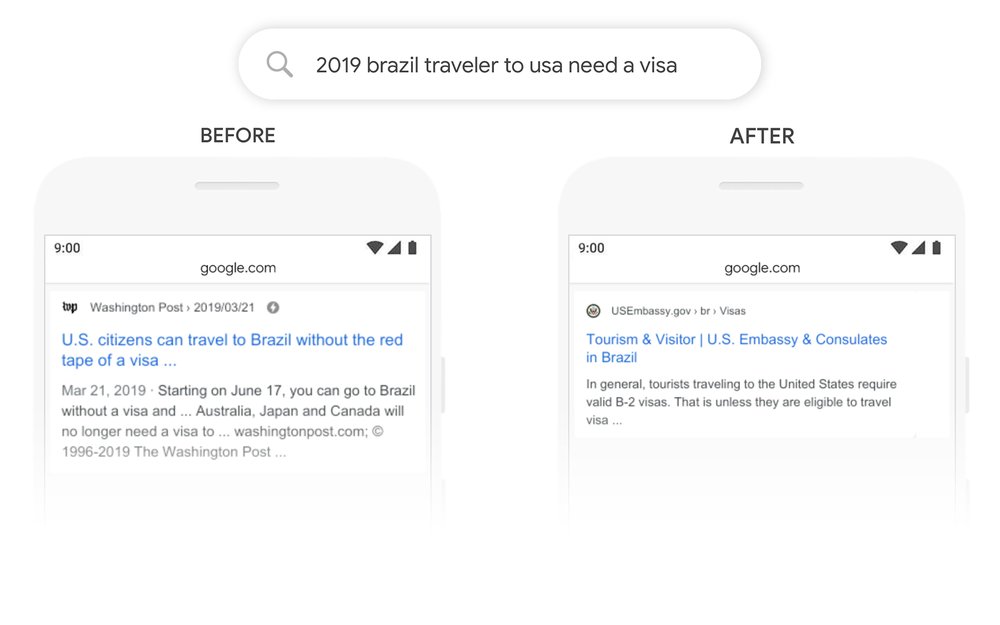
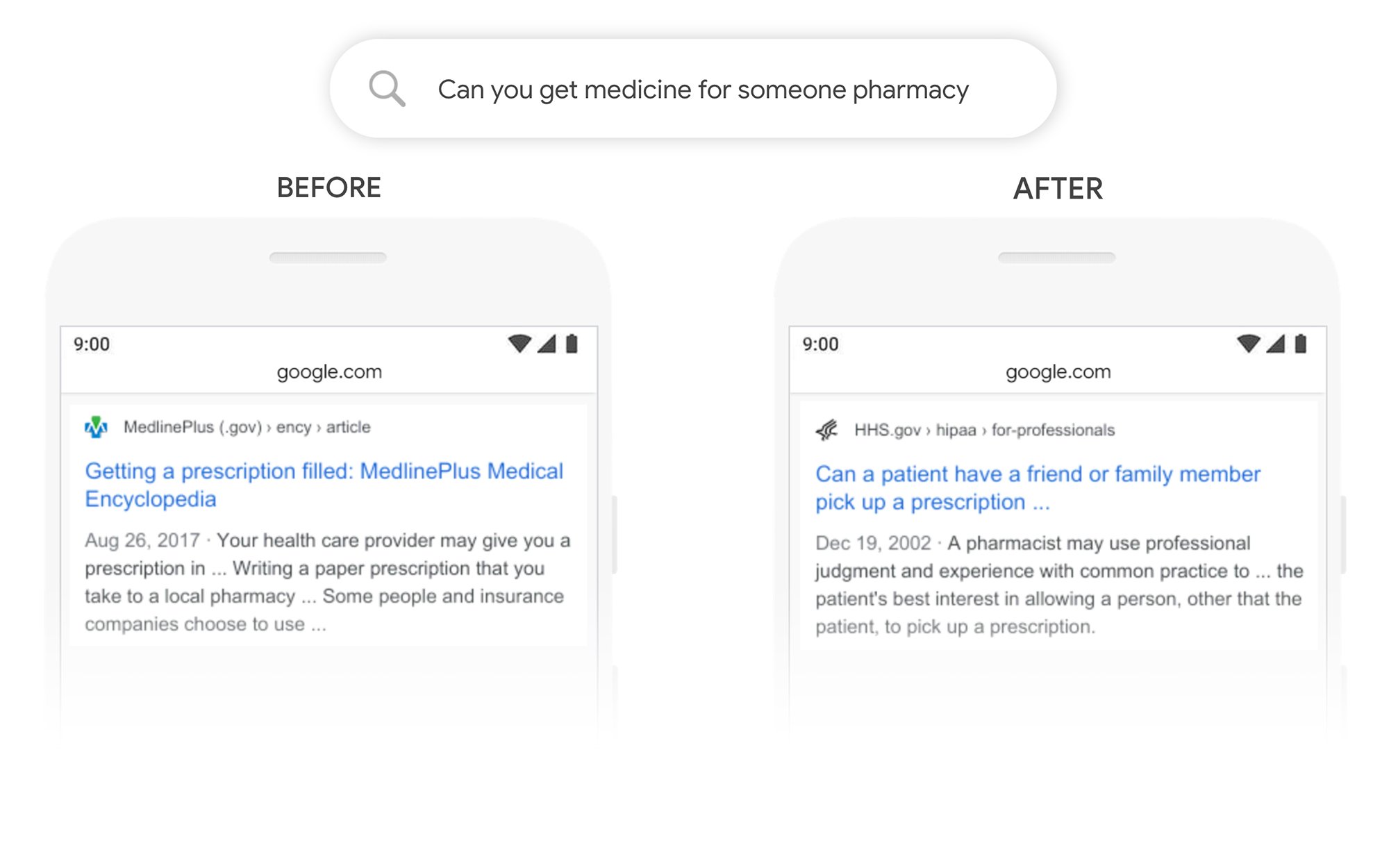
Auch im zweiten Beispiel “Can you get medicine for someone pharmacy” wurde in der Suche vor BERT das Wörtchen “for” ignoriert und man landete auf einer enzyklopädischen Seite, die erklärt hat, wie man verschreibungspflichtige Medikamente bekommt. Mit BERT wird die Frage beantwortet, ob ein Freund oder ein Familienmitglied für einen Patienten verschreibungspflichtige Medikamente abholen kann!
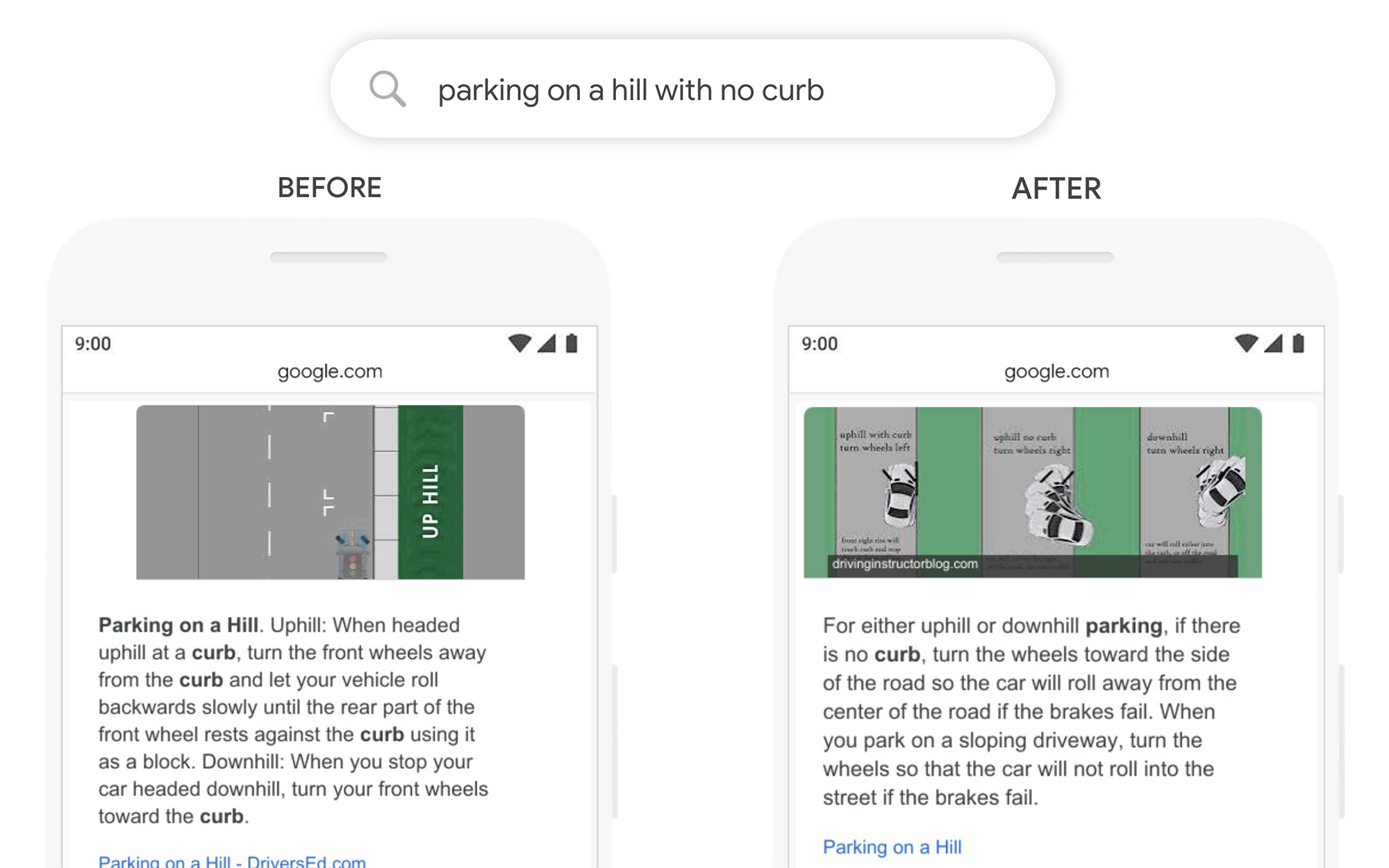
Auch bei der Erstellung von Featured Snippets hilft Googles BERT offensichtlich enorm. In dem Beispiel “parking on a hill with no curb” wurde in der vorherigen Variante die Frage, wie man auf einem Hügel ohne Bordstein parken darf, nicht geklärt, da das Wörtchen “no” ignoriert wurde. Mit BERT kommt nun die richtige Antwort direkt aus der Suchmaschine.
Was ist Googles BERT & wie funktioniert es?
Googles BERT hilft besser zu verstehen, was Wörter in einem Satz bedeuten – mit allen Nuancen des Kontextes. Grundsätzlich setzt Google BERT ausschließlich für sogenannte Conversational Searches und Longtail-Suchanfragen ein, also Suchanfragen, die selten stattfinden, der natürlichen Sprache nahekommen und aus mehreren Wörtern bestehen.
Aus meiner Sicht wird Googles BERT jedoch schon bald bei sehr viel mehr als 10 % der Suchen eingesetzt werden, denn zum einen tut sich eine Menge in der Forschung und zum anderen suchen wir immer mehr in natürlicher Sprache, weil das immer besser funktioniert. Gerade durch die Verbreitung der „Voice Search“ nehmen Suchanfragen in natürlicher Sprache deutlich zu!
Da Googles BERT keinen Einfluss auf das Ranking hat, gibt es folglich auch keine BERT-Penalty und man kann auch nicht direkt für BERT optimieren! Ich würde jedoch dazu raten, kein Geschäftsmodell mehr aufzubauen, das darauf basiert, Nutzer mit geschlossenen Fragen über die Suchmaschine auf die Seite zu holen und dann mit stupider Werbung Geld zu verdienen. Denn Google wird immer mehr Fragen direkt in der Suche beantworten und auch sehr viel mehr Featured Snippets einblenden, die den Klick auf die Website dahinter überflüssig macht.
Langfristig kann man also nur mit echten Analysen, tiefen Erkenntnissen und richtigem Mehrwert eine Daseinsberechtigung in der Suche erhalten.
Die eigenen Web-Dokumente sollten in jedem Fall für Featured Snippets optimiert geschrieben und strukturiert werden, um zumindest die Sichtbarkeit und damit die Chance auf Traffic in der Antwortmaschine Google zu maximieren.
Spannend ist jedoch der Umstand, dass Bing nach eigenen Angaben BERT bereits seit April weltweit einsetzt. Ich gehe davon aus, dass Google auf BERT bei vielen Suchanfragen verzichten kann, da sie auf ausreichend Nutzerdaten als Qualitätsindikator zurückgreifen können, denn Algorithmisch unterscheiden sich beide Suchmaschinen sehr viel weniger, als man vielleicht denken mag. Bei Bing ist die allgemeine Suchergebnisqualität offenbar noch nicht so gut, weswegen BERT bei jeder Bing-Suche weltweit verwendet wird, um die Suchergebnisse zu verbessern.
Wer noch ein paar Ideen für den Einsatz von BERT für die eigene Website und die Verbesserung des eigenen SEOs haben möchte, der wäre wohl besser auf der SEOkomm gewesen ;o)











Ein paar Tools und Tipps verstecken sich aber noch in meinen Folien:
Update: BERT ist nun in über 70 Sprachen live!
Hui, das ging schneller als erwartet! John Müller hatte noch 6 Monate gemutmaßt, doch seit gestern, also den 9.12.2019 liegt die offizielle Bestätigung von Google vor, dass BERT nun in mehr als 70 Sprachen weltweit im Einsatz ist:
Wie könnte es mit BERT und Google weitergehen?
Sollte sich der Trend in Sachen digitaler Assistenten fortführen, wird es über kurz oder lang zu einer deutlichen Zunahme von Sprachsuchen kommen. So verkaufen sich aktuell beispielsweise Alexa-fähige Geräte besser als je zuvor. Amazons Echo Dot und der Fire TV Stick mit Alexa Voice Remote standen am Black Friday wieder einmal an der Spitze aller Verkäufe in den USA. Der Smart Speaker und die Fernbedienung sind die meistverkauften Produkte bei Amazon weltweit und verändern schon heute das Nutzungsverhalten von Millionen von Menschen im täglichen Umgang mit digitalen Geräten. Erst kürzlich gaben Apple, Google und Amazon bekannt, dass sie über den Zigbee-Standard ihre Smart Home Geräte künftig miteinander sprechen lassen wollen.
Daher kann man wohl davon ausgehen, dass Googles BERT schon bald bei sehr viel mehr als 10 % der Suchen eingesetzt werden. Wie bereits eingangs beschrieben tut sich noch eine Menge in der Forschung und zum anderen suchen wir immer mehr in natürlicher Sprache, weil das eben immer besser funktioniert.
Weiterhin wird die verbesserte Fähigkeit der Suchmaschine „die richtigen Antworten“ zu identifizieren möglichweise zu einem starken Anstieg bei der Integration der sogenannten „Featured Snippets“ führen, was für die rankenden Webseiten häufig mit einer Abnahme des Traffics aus der Suchmaschine einhergeht. Google wird hiermit immer mehr Fragen direkt in der Suche beantworten, was dem Nutzer den Klick auf die Website dahinter erspart. Dadurch treten immer mehr Zielkonflikte zwischen Google und Webseitenbetreibern zutage. Zwar kann eine Webseite, die die eigenen Web-Dokumente für die „Featured Snippets“ optimiert geschrieben und strukturiert hat, zwar Sichtbarkeit und zumindest die Chance auf Traffic in der Antwortmaschine Google maximieren, mittelfristig könnte Google jedoch mit dem eigenen Wissensgraph immer mehr Geschäftsmodelle obsolet machen.
Spätestens wenn Google dazu übergeht, aus den strukturierten Daten der Webseitenbetreiber und unstrukturierten Informationen der Webseiten das inhärente Wissen zu extrahieren, das zur Vervollständigung des Knowledge Graphs fehlt, braucht es ein neues Verhältnis zwischen den Inhalts-Lieferanten und der Verwertung dieser seitens Google. SEOs liefern schon heute durch die Einbindung des FAQPage-Schemas ideale Trainingsdaten für eine echte Antwortmaschine der Zukunft. Das Dreigespannt aus Text (der Webseite), Frage und vollständiger Antwort ist genau das, was im SQuAD-Datensatz benutzt wird, um die NLP-Algorithmen zu trainieren und anschließend zu evaluieren. Hier bietet sich den Suchmaschinenoptimierern ein mögliches Fenster, die eigenen Wahrheiten über diese Trainigspaare zur Wahrheit von Google werden zu lassen. Googles Aufforderung in den Richtlinien dieser Fragen und Antworten Funktion nicht werblich einzusetzen „FAQPage darf nicht zu Werbezwecken verwendet werden.“ lässt jedoch den Schluss nahe, dass diese nicht ungefiltert verwendet werden.
BERT vervollständigt den Knowledge Graph
Eine aktuelle Forschungsarbeit zeigt beispielsweise, dass man BERT auch zur Vervollständigung von Wissensgraphen einsetzen kann, indem man statt regulärer Texte einfach sogenannte Knowledge-Triples verwendet. Wissensgraphen wie FreeBase, das die Basis von Googles Knowledge Graph darstellt, aber auch YAGO und WordNet stellen eine wichtige Basis für viele KI-Aufgaben dar, beispielsweise semantische Suche, Empfehlungssysteme oder auch die Beantwortung von Fragen. Ein Knowledge Graph ist typischerweise ein multirelationaler Graph, der Entitäten als Knoten und Beziehungen als Kanten darstellt. Jede Kante wird als Triplett dargestellt, was die Beziehung zwischen zwei Endverbindungen anzeigt, z.B. „Steve Jobs, [hat gegründet], Apple Inc.“. Drei Forschern der NU, die sich mit neuesten KI Algorithmen anwendungsbezogen für den Bereich Medizin beschäftigen, ist es nun gelungen das vortrainierte Sprachmodell BERT für die Vervollständigung von Wissensgraphen zu verwenden. Deren Methode nimmt Entitäts- und Relationsbeschreibungen eines Tripels als Input und berechnet die Bewertungsfunktion des Tripels mit dem KG-BERT Sprachmodell.

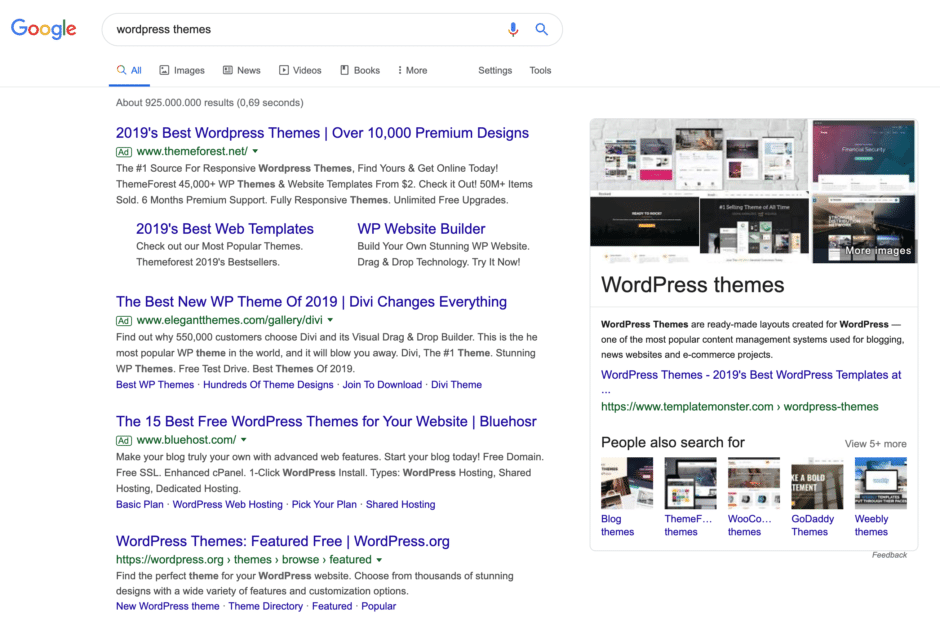
Das Thema Semantik und damit Entitäten und deren Beziehungen wird also auch im Bereich SEO zunehmend wichtiger. In der englischsprachigen Suche beeinflusst diese neue Form der Wissensgenerierung bereits massiv die Ausgabe des Knowledge Graph. Wie im Beispiel unten zu sehen, wird die Suchanfrage „wordpress themes“ bereits mit einem Knowledge Graph Panel in der rechten Spalte dargestellt, mit der Entität „WordPress themes“ für die offenbar templatemonster.com die höchste Relevanz besitzt, obwohl diese Webseite in der organischen Suche lediglich auf Platz 4-6 rankt! In der mobilen Suche wird das Knowledge Graph Panel in der Regel über den organischen Ergebnissen eingeblendet, was die Bedeutung dieser Entitätserkennung und -zuordnung weiter steigert.
Ein Blick auf die derzeitigen NLP-APIs, die Google seinen Kunden als Dienstleistung anbietet, lässt einige Rückschlüsse auf derzeitige Möglichkeiten und Fähigkeiten der Suchmaschine zu. So lässt sich beispielsweise in der Dokumentation der Cloud NLP-API eine vollständige Liste der Inhaltskategorien einsehen, die für die Methode classifyText zurückgegeben wird. Diese Kategorien könnte Google beispielsweise in der Suche für das Clustering von Webseiten verwenden, um themenspezifische BERT-Varianten zu trainieren. Daher ist der Blick auf die gelieferten Kategorien und dessen „Confidence Score“ für jeden Suchmaschinenoptimierer ein gefundenes Fressen. Hier sagt Google quasi selbst, zu welchem Themenbereich es einen Text zuordnet und wie sicher sich die Suchmaschine dabei ist!
Wer noch ein wenig visionärer auf das Thema SEO in der Zukunft blicken möchte, sollte sich noch die Google Vision API und deren Möglichkeiten ansehen. Spätestens wenn in ausreichend vielen Haushalten Googles Smart Home Geräte mit offenen Kameras und Mikrofonen stehen, könnte Google die Erwähnung von Marken und Produkten im echten Leben in die Suchergebnisse einfließen lassen. Die Vision API kann sogar anhand von Mimik, Gestik und der Stellung von Augen und Pupillen erkennen, ob wir uns für ein Produkt, eine Marke, eine Meinung oder eine Person begeistern, oder uns eine Antwort aus der Suchmaschine vielleicht enttäuscht oder sogar verärgert. Vielleicht kommen schon bald Dienstleister auf die Idee mit bestimmten Produkten durchs Bild zulaufen, um deren Relevanz zu steigern. Das neue Linkbuilding findet also auch in der echten Welt statt und es wird immer stärker wichtig, den Menschen ins Zentrum seiner Anstrengungen zu nehmen.
Das mag alles ziemlich abgefahren klingen, aber genauso wie Menschen überschätzen was in zwei Jahren möglich ist, unterschätzen sie häufig massiv was in zehn Jahren möglich sein wird.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




